spss的描述統計
Frequencies次數分配表的特色是可以作百分位數,未來作項目分析的時候做極端值比較,例如像是前1/3,後1/3的比較
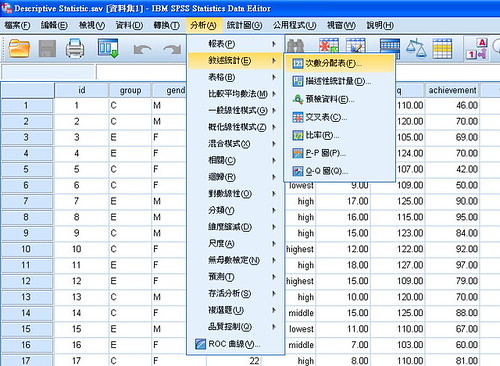 PR值(percentile ranks),是一種名次的概念,百分位數是分數的概念,是等距變項,PR值不是等距的,是名次概念變數檢視等於是右鍵內容,把每個行與列的特性給定義,是文字還是數字
次數分配表,來源變項清單,可以按下ctrl來選個別,總和是把某個變項的受試者全部加起來
變異量數有包含標準差、變異數、最大值最小值,全距在框框裡稱為叫範圍
分配看偏態係數(正偏或者)峰度是高陜或者低闊峰,四分位數會出現第25%的、75、50..或者可以定義百分位數第27、73的前1/3的人是要找百分位數67,後1/3是要找百分位數33
名義變項會用長條圖,每個bar中間會有空間,智商與學習成就是連續變項,建議一開始先選兩個變項,名義變項與連續變項分開跑圖形,圓餅圖是適合名義變項
依觀察值遞增或者遞減是從人數最多或者最少的開始排,如果要分組(男生女生)要改用別的指令
眾數可以多個,50分有12個,30分也有12個
標準差的平方是變異數
偏態和峰度系數取絕對值小於等於1為常態分配,等於0剛好是常態分配,離0越遠越不是常態
C是控制組,E是實驗組,若希望輸出結果(例如1代表非常同意、2代表同意)可以到編輯,選項,執行之前把輸出標記改成名稱與標記,數值要值與標記
按下套用與確定
如果希望表格上面顯示出來1=男生,2=女生這樣的註記,記得在問券輸入編碼的時候不要使用文字C、E(控制組實驗組),記得直接用1,2來編碼,這樣才會跑出來
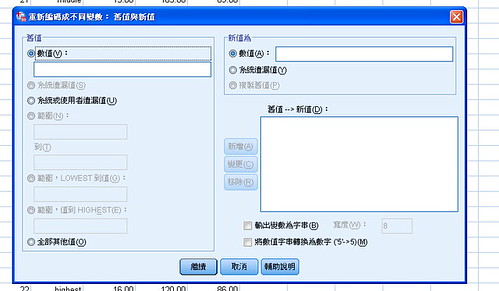
如果不小心已經都用文字來編碼(C=控制組),還可以用轉換→重新編碼成不同變數(不會蓋掉原本的),
PR值(percentile ranks),是一種名次的概念,百分位數是分數的概念,是等距變項,PR值不是等距的,是名次概念變數檢視等於是右鍵內容,把每個行與列的特性給定義,是文字還是數字
次數分配表,來源變項清單,可以按下ctrl來選個別,總和是把某個變項的受試者全部加起來
變異量數有包含標準差、變異數、最大值最小值,全距在框框裡稱為叫範圍
分配看偏態係數(正偏或者)峰度是高陜或者低闊峰,四分位數會出現第25%的、75、50..或者可以定義百分位數第27、73的前1/3的人是要找百分位數67,後1/3是要找百分位數33
名義變項會用長條圖,每個bar中間會有空間,智商與學習成就是連續變項,建議一開始先選兩個變項,名義變項與連續變項分開跑圖形,圓餅圖是適合名義變項
依觀察值遞增或者遞減是從人數最多或者最少的開始排,如果要分組(男生女生)要改用別的指令
眾數可以多個,50分有12個,30分也有12個
標準差的平方是變異數
偏態和峰度系數取絕對值小於等於1為常態分配,等於0剛好是常態分配,離0越遠越不是常態
C是控制組,E是實驗組,若希望輸出結果(例如1代表非常同意、2代表同意)可以到編輯,選項,執行之前把輸出標記改成名稱與標記,數值要值與標記
按下套用與確定
如果希望表格上面顯示出來1=男生,2=女生這樣的註記,記得在問券輸入編碼的時候不要使用文字C、E(控制組實驗組),記得直接用1,2來編碼,這樣才會跑出來
如果不小心已經都用文字來編碼(C=控制組),還可以用轉換→重新編碼成不同變數(不會蓋掉原本的),
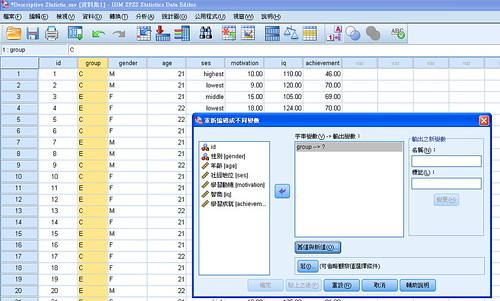 (group取個新名字,要按下"變更",再按好)
論文中表格最好都是中文,不要用CE
小數點取到第二位就可以了
APA格式有些不能用SPSS跑過就好了,某些沒有線,有些有線,有自由度等值要補上、顯著的數字或者合併
如果欄和列要交換可以貼到excel(回去查方法),或者可以SPSS在輸出的框框裡點兩下編輯,在樞軸表,選樞軸,裡面選轉置,就可以X和Y軸行和列交換
Descriptives敘述性統計量(能跑Z分數)
Z分數可以算連續變項的標準分數,名義變項的標準分數不能算(例如性別沒辦法算標準差)
分析→敘述統計→描述性統計量(只能用在連續變項)→學習
成就溝選「將標準的數值變成變數」=計算Z分數,然後按下選項按鈕
在敘述統計量的視窗中會看不到名目選項(無法計算)
(group取個新名字,要按下"變更",再按好)
論文中表格最好都是中文,不要用CE
小數點取到第二位就可以了
APA格式有些不能用SPSS跑過就好了,某些沒有線,有些有線,有自由度等值要補上、顯著的數字或者合併
如果欄和列要交換可以貼到excel(回去查方法),或者可以SPSS在輸出的框框裡點兩下編輯,在樞軸表,選樞軸,裡面選轉置,就可以X和Y軸行和列交換
Descriptives敘述性統計量(能跑Z分數)
Z分數可以算連續變項的標準分數,名義變項的標準分數不能算(例如性別沒辦法算標準差)
分析→敘述統計→描述性統計量(只能用在連續變項)→學習
成就溝選「將標準的數值變成變數」=計算Z分數,然後按下選項按鈕
在敘述統計量的視窗中會看不到名目選項(無法計算)
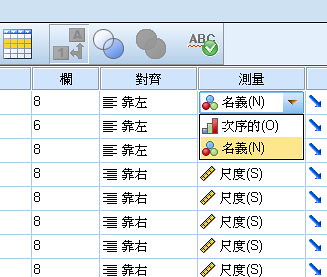 名目選項可以在"不同欄位"去更改
如果你要把要做同樣的步驟的資料分析,可以把語法檔存起來,可以選「貼上之後」(幫你把剛剛選擇的選擇項目重作),此時只有跑出語法視窗,還要按下執行才會跑出報表
Z分數會在資料分析視窗,不會在輸出檔,Zachievement就是Z分數
Explore是預檢資料,做資料檢查、資料預檢之用,特色是可以按照組別來(男生組自己跑,女生組自己跑以及全體一起跑),可以找偏離值(Outliers),有盒狀圖,可以做
如果要跑組別自己的資料可以把智商放第一個依變數清單,勾選統計量,裡面有信賴區間95%,M估計值比平均數中數更
能精確反映,當是用在偏離常態的狀況時,如果發現偏態並不是常態,那就看M估計值
如果假設考驗的結果是
利用統計軟體來跑就是使用P值法
H0虛無假設是偏態係數是否等於0(常態分配)
H1對立假設是偏態係數不等於0
P值法:阿法設定=.05
ANOVA=變異數分析,裡面有個F值,F值使因為就是R.A. Fisher這個人所建立的
P值是小於0.05代表落入虛無假設(常態分配圖上兩邊的虛無假設中)把p值去跟阿法值相比,P<阿法要拒絕虛無假設
p值若大於阿法值(通常設為0.05),代表在中間這塊,要接受h0,偏態係數=0,為常態
常態性檢定,顯著性=P值=0.09,P>阿法,偏態係數相當於0,為常態分配,所以接受H0,智商是呈常態分配
下午茶的故事:這幾位統計學家(英國),在喝下午茶,先倒入紅茶再放入牛奶,有位女士經過,跟他說先放牛奶再沖紅茶比較好喝,這幾位統計學家就想試驗看看,沖了20杯奶茶,讓她喝猜看看,結果20杯她只猜錯一杯,所以就是0.05....代表她是對的,仍分得出來先沖茶還是先沖奶比較好喝
summarize不教,少用
Means可以分組作統計量,可以做T考驗、變異數分析,考驗
兩個連續變項有沒有線性關係
(分析→比較平均數法→平均數)
例如想看智商在男女上有沒有差別,就把智商放第一個框框,第二個框框放組別,裡面勾選Anova表格會做變異數分析
,如果智商和組別都是連續變項才可以勾線性關係的檢定(但是兩者都不是)
Anova摘要表的平均平方和要改為平均值,F檢定請改為F值,sig.就是P值
若F值為3.209,P值為.08,控制組和實驗組是沒有差異的,雖然在報表中兩組的智商是120和111,但是其實智商差個9
是沒有差異的
H0:F=0
H1:F不等於0
如果是0.03代表控制組的智商是顯著高於實驗組的
比較兩組的時候,t平方=F,F開平方=t
因此F考驗相當於t考驗的結果
如果平均數、中位數跟M算出來四種估計值差很多,代表他不是常態分配
在50個人95%的人智商是落在114~118之間
勾選偏離值是最大個五個人、最小的五個人會去除掉,刪除
兩極端各5%觀察值平均數
考驗智商此變項是否偏離常態分配請勾選「常態機率圖附檢定」
M估計值
莖的寬度是10 wtem width 10,請莖加葉,
名目選項可以在"不同欄位"去更改
如果你要把要做同樣的步驟的資料分析,可以把語法檔存起來,可以選「貼上之後」(幫你把剛剛選擇的選擇項目重作),此時只有跑出語法視窗,還要按下執行才會跑出報表
Z分數會在資料分析視窗,不會在輸出檔,Zachievement就是Z分數
Explore是預檢資料,做資料檢查、資料預檢之用,特色是可以按照組別來(男生組自己跑,女生組自己跑以及全體一起跑),可以找偏離值(Outliers),有盒狀圖,可以做
如果要跑組別自己的資料可以把智商放第一個依變數清單,勾選統計量,裡面有信賴區間95%,M估計值比平均數中數更
能精確反映,當是用在偏離常態的狀況時,如果發現偏態並不是常態,那就看M估計值
如果假設考驗的結果是
利用統計軟體來跑就是使用P值法
H0虛無假設是偏態係數是否等於0(常態分配)
H1對立假設是偏態係數不等於0
P值法:阿法設定=.05
ANOVA=變異數分析,裡面有個F值,F值使因為就是R.A. Fisher這個人所建立的
P值是小於0.05代表落入虛無假設(常態分配圖上兩邊的虛無假設中)把p值去跟阿法值相比,P<阿法要拒絕虛無假設
p值若大於阿法值(通常設為0.05),代表在中間這塊,要接受h0,偏態係數=0,為常態
常態性檢定,顯著性=P值=0.09,P>阿法,偏態係數相當於0,為常態分配,所以接受H0,智商是呈常態分配
下午茶的故事:這幾位統計學家(英國),在喝下午茶,先倒入紅茶再放入牛奶,有位女士經過,跟他說先放牛奶再沖紅茶比較好喝,這幾位統計學家就想試驗看看,沖了20杯奶茶,讓她喝猜看看,結果20杯她只猜錯一杯,所以就是0.05....代表她是對的,仍分得出來先沖茶還是先沖奶比較好喝
summarize不教,少用
Means可以分組作統計量,可以做T考驗、變異數分析,考驗
兩個連續變項有沒有線性關係
(分析→比較平均數法→平均數)
例如想看智商在男女上有沒有差別,就把智商放第一個框框,第二個框框放組別,裡面勾選Anova表格會做變異數分析
,如果智商和組別都是連續變項才可以勾線性關係的檢定(但是兩者都不是)
Anova摘要表的平均平方和要改為平均值,F檢定請改為F值,sig.就是P值
若F值為3.209,P值為.08,控制組和實驗組是沒有差異的,雖然在報表中兩組的智商是120和111,但是其實智商差個9
是沒有差異的
H0:F=0
H1:F不等於0
如果是0.03代表控制組的智商是顯著高於實驗組的
比較兩組的時候,t平方=F,F開平方=t
因此F考驗相當於t考驗的結果
如果平均數、中位數跟M算出來四種估計值差很多,代表他不是常態分配
在50個人95%的人智商是落在114~118之間
勾選偏離值是最大個五個人、最小的五個人會去除掉,刪除
兩極端各5%觀察值平均數
考驗智商此變項是否偏離常態分配請勾選「常態機率圖附檢定」
M估計值
莖的寬度是10 wtem width 10,請莖加葉,
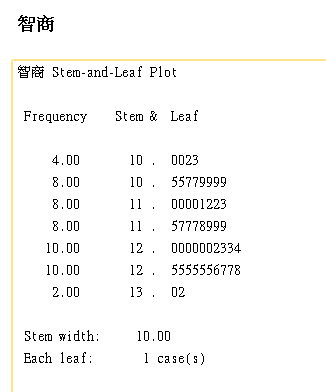 代表有112和113兩個智商(10X10+2,10X10+3)
盒形圖有人的得分,是盒長的1.5倍會出現圈圈,是盒長的3倍,會出現星星,代表極端值,上面標示哪一號是極端值
盒狀圖中間那條線是中位數,盒子的上端線是Q3,盒子的下端是Q1
遺漏值的處理方法
ID 變項1 變項2 變項3
1 3 ● ●
2 ● 4 5
3 5 ● 5
4 ● 3 4
1. 完全排除觀察值 會只剩下一個受試者(會大量移失受試者)
2. 成對排除法:只有被你納入分析的變項才會排除掉,我選第一個和第三個變項會有兩個受試者(選這個比較好)
3. 報表值(會把有遺漏的列出來)
代表有112和113兩個智商(10X10+2,10X10+3)
盒形圖有人的得分,是盒長的1.5倍會出現圈圈,是盒長的3倍,會出現星星,代表極端值,上面標示哪一號是極端值
盒狀圖中間那條線是中位數,盒子的上端線是Q3,盒子的下端是Q1
遺漏值的處理方法
ID 變項1 變項2 變項3
1 3 ● ●
2 ● 4 5
3 5 ● 5
4 ● 3 4
1. 完全排除觀察值 會只剩下一個受試者(會大量移失受試者)
2. 成對排除法:只有被你納入分析的變項才會排除掉,我選第一個和第三個變項會有兩個受試者(選這個比較好)
3. 報表值(會把有遺漏的列出來)
信度 因為每個測驗都會有誤差值,理論上說無限次的分數誤差值總為零 信度是分數測驗結果的一致性或者穩定性,一個受試者做兩份,或是一個團體抽一些人 冷氣或者照明會是一種影響而產生的誤差,稱為系統誤差(大家一起變低分或者高分),系統性誤差不會影響信度 隨機誤差是一種個別誤差 信度係數是用相關係數r來表示 包括: 重測信度=穩定信度=再測信度(用皮爾森相關係數,時間越短相關係數越高,越相關,誤差來源為時間) 複本信度=等值係數=(兩個測驗的內容等值,同一時間去測,誤差來源為內容) 重測副本信度,結合前面兩個(等值的兩個測驗在不同時間測量同一個群體,誤差來源又有時間和內容) 內部一致性係數(只有一次失測):包含折半辦法、庫李法 在論文中 要做複本信度要講題目到底多少題,10題的題目就0.8那麼變成20題那麼信度會更高 做重測信度要講時間隔多久,因為時間會影響 要依照測驗的性質,例如人格,三個月前後施測應該相關很高 成就測驗可能變動很大,不能隔太久 折半信度會有很大的問題,50個題目如何拆成各25題有非常多個折半信度,要用哪種呢?所以不要 庫李法是適用於對錯是非、或者只有同意或者不同意(適合用於成就題目),在SPSS裡面沒有可以用阿法法 阿法法(適用於李克特五點量表) 如何用SPSS跑信度 原理: 兩個變項之相關,最好先看要看是否線性關係,用散布圖,如果是沒有線性關係的去跑皮爾森係數會等於0 變異數是算個別分數在群體中的變動情況,個別分數減掉平均數 共變數 標準化之後 -1小於等於r小於等於1 Pearson積差相關可以算 直線相關 重測信度、複本信度 內部一致性 建構效度 預測 Spearman兩個變項 肯德爾的和諧係數適用於多個評分者 重測 複本 重測複本 分析analyze→相關correlate→雙變數bivariate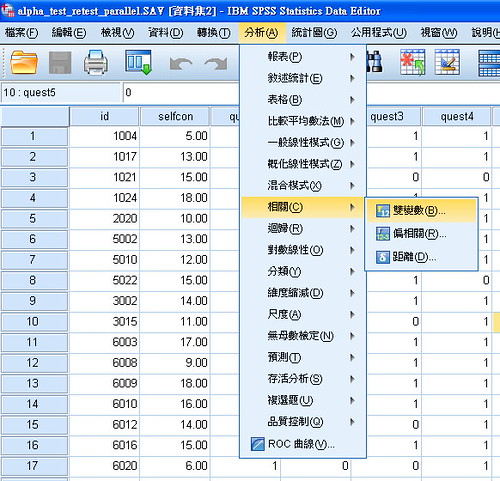 老師是用alpha test retest parallel這個資料檔來跑測驗
重測信度用相關係數 pearson r
math1和math2是重測信度(同分測驗同個團體在不同時間做)
分析→雙變數點選math1和math2,勾選(pearson)相關係數
顯著性測驗就是
雙尾檢定時,阿法值為0.05/2=0.025較嚴格,如果只差一點點會落入虛無假設,又有文獻中很明確知道這個測驗一定是正相關或者負相關,可以改為單尾檢定
信度不用做單尾或者雙尾顯著
老師是用alpha test retest parallel這個資料檔來跑測驗
重測信度用相關係數 pearson r
math1和math2是重測信度(同分測驗同個團體在不同時間做)
分析→雙變數點選math1和math2,勾選(pearson)相關係數
顯著性測驗就是
雙尾檢定時,阿法值為0.05/2=0.025較嚴格,如果只差一點點會落入虛無假設,又有文獻中很明確知道這個測驗一定是正相關或者負相關,可以改為單尾檢定
信度不用做單尾或者雙尾顯著
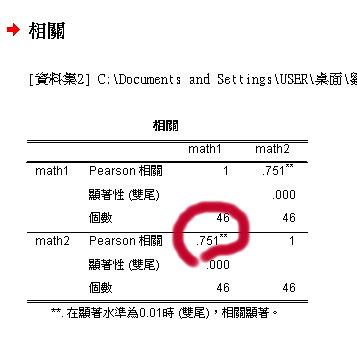 信度的寫法:
數學1和數學2的相關是0.751 r=0.751,他們的重測信度是0.751
如果改成身高和體重的相關,則p=0.000代表後面還有東西,代表p小於0.001,(SPSS只能顯示三位小數點)
信度的寫法:
數學1和數學2的相關是0.751 r=0.751,他們的重測信度是0.751
如果改成身高和體重的相關,則p=0.000代表後面還有東西,代表p小於0.001,(SPSS只能顯示三位小數點)
 相關係數的寫法:
樣本的相關r=.751
阿法=0.05
代表這兩個變項有顯著相關p小於等於阿法
虛無假設:母群體的相關是0,對立假設
p小於等於阿法要拒絕h0
p大於等於阿法要接受h0
r平方等於決定係數
第一次和第二次的重疊的部分只有49%
如果是0.751平方
SPSS跑複本信度
分析→相關→雙變數
read1a和read1b
確定
就是複本信度
=0.817
相關係數的寫法:
樣本的相關r=.751
阿法=0.05
代表這兩個變項有顯著相關p小於等於阿法
虛無假設:母群體的相關是0,對立假設
p小於等於阿法要拒絕h0
p大於等於阿法要接受h0
r平方等於決定係數
第一次和第二次的重疊的部分只有49%
如果是0.751平方
SPSS跑複本信度
分析→相關→雙變數
read1a和read1b
確定
就是複本信度
=0.817
 內部一致性信度分析
分析→尺度→信度分析
選擇題目1~15(題目的數值會是1和0)
模式看要折半信度或者阿法法
若有15題程式會拆成七題和八題(spearman-brown係數要選不等長的)
0.668是前八題的,
折半信度校正過後的是斯布校正公式
如果題目是16題要選等長的spearman-brown係數
15題如果要選單數題和雙數題的折半信數,就選1、3、5、7、9、11、13、15完再選2、4、6、8、10、12、14,這樣就可以跑
要跑庫李信度也是一樣不用管勾選題號順序跑阿法值就可以了
如果有勾選差機離差代表(x-x的平均)(y-y平均)總和,再除N,會出來共變數
11.13
內部一致性信度分析
分析→尺度→信度分析
選擇題目1~15(題目的數值會是1和0)
模式看要折半信度或者阿法法
若有15題程式會拆成七題和八題(spearman-brown係數要選不等長的)
0.668是前八題的,
折半信度校正過後的是斯布校正公式
如果題目是16題要選等長的spearman-brown係數
15題如果要選單數題和雙數題的折半信數,就選1、3、5、7、9、11、13、15完再選2、4、6、8、10、12、14,這樣就可以跑
要跑庫李信度也是一樣不用管勾選題號順序跑阿法值就可以了
如果有勾選差機離差代表(x-x的平均)(y-y平均)總和,再除N,會出來共變數
11.13
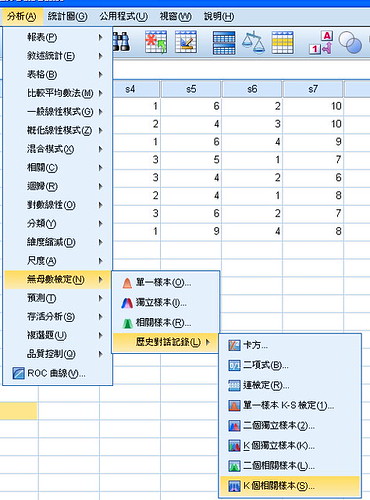 分析→無母數分析→歷史對話紀錄(在SPSS12以後有多一層)→K個相關樣本
分析→無母數分析→歷史對話紀錄(在SPSS12以後有多一層)→K個相關樣本
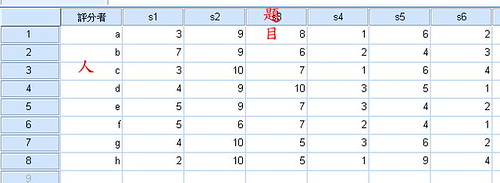 之後補上
之後補上
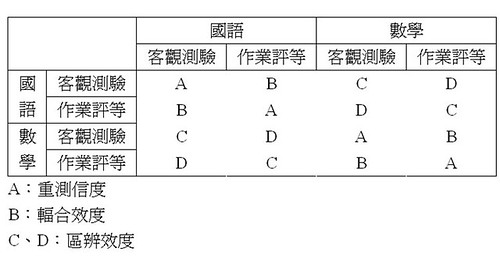 重測信度、輻和信度、區辨效度(又有分為同特質相同方法和不同特質不同方法)
應該要A>B>C>D
生涯自我效能量表有分為
信心強度
難度知覺
推論性
那麼個別(信心強度)和問卷總分的相關要很高,但是個別層面(信心強度、難度知覺、推論性)之間不能相關很高,相關很高代表沒有區別了
11.26
做問卷的流程:
試題給專家審閱
修正完給未來要施測的母群體做預試
此時項目分析會很重要,它能讓你檢視你的題目好不好
項目分析很重要
項目分析分為質與量化,質的部分是要先給專家檢視,再來要給未來施測的母群體做預試,如果你本來的樣本就很小只有一個班或者少數人,此時可以換成類似各種條件(學區、年齡、特質)的群體來施測
預試施測一定要自己來,這樣受試者如果有反應你可以馬上收到意見修正,叫別人幫你做也許不會反應給你
好的研究工具標準差要大
預試可以為構念中最長題目的五倍(我的指導教授是說100份),如果後面有要做高分組低分組,每組至少要有30人,如果後面想做因素分析,大約至少要200分,如果你的樣本沒有超過200個根本不用做因素分析了,總人數沒有到90個人,這樣高低組根本沒有30個也不用做極端值t考驗了
遺漏質會產生可能有兩種情況,第一個是題目太難、描述太難導致受試者看不懂不之如何回答,第二種是太隱私使受試者不願意回答,此時就要修改題目到可以容易閱讀或者不那麼敏銳地問到想問的
如果你要了解的群體是常態分佈的,集中量數要在中間,如果是有某些問題的議題或族群(例如要做行動研究),他們的集中量數是要偏低的才算合理,變異量數會是小的(大家都答錯都不好)
如果你預試有50題很多,最後希望有25題,這時候會砍掉的題目很多,標準差的範圍就可以設小一點,超出太多的就砍,相反的如果你只能踢掉三題,那麼即使跟大家差很多,還是要留下來
檢查的方式,使用次數分配表裡面的描述統計來看遺漏值(偏態和峰度要自己打勾),選好所有的題目進框框,看第一題的框框,遺漏值=5代表有第一題五個人漏答了,請整理每個題目是甚麼,漏答率有多少
要整理成表格可以在輸出的表格點兩下,藉由右鍵→樞軸→轉置,就會左邊列是題目,右邊是,偏態的標準誤、峰度、峰度的標準誤都可以可以刪除
遺漏值有些問卷有提供非常滿意、滿意、不滿意、非常不滿意、無法作答,此時無法作答跟沒答都列為遺漏值
(會有無法作答是因為這個問卷的特性,並不是每個都問卷都需要)
通常遺漏值可以用個位數的最大值例如9,通常一開始就要設定遺漏值是多少(例如年齡,就寫99是遺漏值)
系統遺漏跟無法作答會歸類在一起
用item analysis這個檔案,以後要用預試就可以用這個檔案的格式
改一下編輯→選項→輸出標記改成「值與標記」可以看到每個代表什麼(1=非常同意,2=同意.....)
kelley統計學者提出是用前27%和最後27%作為界線是最有鑑別度,首先找總分多少,再來用百分位數用第73百分位數(PR=73),只要大於等於PR73的都叫做高分組,再找到PR只要低於27的都叫做低分組
如果兩組的平均數差異比較,用獨立樣本T考驗,如果有前後測但是是同一組,用相依樣本T考驗
也就是假設高分組的平均和低分組的平均,應該要高分組的平均要顯著高於低分組的平均
如何找出適合的好試題保留?
小樣本分析是用來考驗兩組極端組的得分平均,步驟如下:
1. 計算每題的總分
2. 找出高低分組
3. 使用獨立樣本T考驗(如果不顯著就可以剔除)
有顯著考驗才算好試題
4. 判斷
除了看是否簡述外,大樣本時可以找critical ratio臨界比,把T值取絕對值,如果是大於三的才可以算是好試題
用compute
選百分位數
轉換
作法:
1. 轉換→計算變數→統計→mean(用mean而不是sum這樣會幫妳寫回1~4選項,而不是平均分數,會幫你踢掉遺漏質),新增一個total
2. 分析→敘述統計→次數分配表,選剛剛新增的total→統計量→百分位數=27和73
3. 轉換→重新編碼成不同變數→選total,名稱打上組別,標記為極端組分組,按下變更,再按新質與舊質,選範圍,值到highest,2.9904.選新值為2(高分組),再設低分組
在按確定
新的組別中有
不想看到小數點可以到變數檢視裡面把小數點的位數改為0,把值得部分寫好1=高分組
平均數的差異除以標準誤就是T值的概念
分析→獨立樣本T考驗
獨立樣本T考驗作法:
獨立樣本T考驗→選好所有題目過去,分組變數選極端組分組,使用指定的數值裡放1和2,放相反也沒關係,只是T值的正負問題
定義組別1放2(高分組),組別2放1(低分組),並不影響顯著差異,只是看高分組減低分組還是相反
每組的人數不太相同是正確的
看第二個表格獨立樣本檢定,看到t那欄,顯著性是p值,如果樣本是隨機抽取而來的,第二個變異數要同質,第三個要常態分配,這樣才能用t檢定
因此t值有兩個是因為,公式幫你校正
如果高分組都是3.59分,低分組又有1分又有3分
如果Levene的顯著性p值是大於0.05
以第一題為例,
F檢定 顯著性 t 自由度 顯著性(雙尾)
.238 .627 14.655(=14.66) .000
14.683
當F檢定旁的顯著性如果是大於0.05要看上面那個t的數字
如果是小於等於0.05要看下面那個t的數字
t要寫作 14.66***
因為顯著性雙尾如果小於0.5是*,小於0.1是**,小於0.01(.000代表0.0000000XXX)是***
最後要標回去14.66***
同質性檢驗要把態度構念的項目加總和全部題目的相關、行為構念的項目加總和全部題目的相關(都要高才對),不要把全部題目跟總分直接相關,除非他們構念完全相同
題目和總分的相關:
分析→尺度→信度分析→選50題。統計量那裏勾選刪除項目後之量尺摘要(出來的報表代表刪掉自己這題之後,其他題目和總分的平均數或相關),這樣的相關比自己和50題的相關更嚴謹,這是校正後的題目總分相關(扣掉自己了)
.944
考題舉例:
如果老師的題目標準是0.4,修正的項目總相關是0.4以下的題號就要刪除了
sort描述性統計量,可以算出Z分數
因素負荷量:
分析→維度縮減→因素→移入題目→萃取→主成分→固定因子數目:1,確定,報表請拉到最後,看成分矩陣a,填回因素負荷
因素分析法最起碼要0.3
刪題標準可以用:
用遺漏值5%:
平均數的上下範圍:敘述統計選total選平均數和標準差,用一個標準差之內2.71+0.47~2.71-0.47,=2.24~3.18,之外的叫做不好
標準差:越大越好,所以標準為0.83,小於等於0.83的要去掉(可以刪掉十個)
偏態希望可以常態分配,所以偏態係數絕對值大於1的不能要(都可以要)
極端組t檢定(臨界比)若用3(看絕對值)只能刪掉幾題,甚至可以
相關:0.3以下的刪除(含0.3)
所以每題被圈了幾次,圈很多就很不好,老師會問如果只能刪1題,刪第5題會刪掉哪些題目
--
12.11
老師說測量研究第三個作業,如果你的論文用不到這樣的測驗工具,那可以兩人一組,如果論文題目也訂了
難度分析,難度的數字越大代表越簡單,最高是1,也就是100% ,有兩種算法,第一種是通過的人佔全體多少比率,第二種算法是高分組裡面的通過人數除以高分組的人數加上低分組通過人除以低分組總人數再除以2(高分組的通過率+低分組的通過率再除以2)
鑑別度是高分組的答對率減低分組的答對率
先算總分,算出PR然後算出大於27
通過率:
1. 高分組低分組,選擇高分組算出答對的,用次數分配那些人答對,計算有芬的是那些人,最後相加除二,鑑別度則是兩個相減
2. 等級觀察值,選擇某一組看答對率,用分割檔案也可以,每個組別都幫你做一次
檔案在Item analysis壓縮檔中 diffically這個SPSS檔案:有十個題目,答對是1 ,如果你的題目是四個選項的可以用轉換,答對的給1,答錯的給0
要先算總分:轉換→計算變數→自己寫目標變數為total統計→點兩下sum 自己key v1 to v2 。(設立一個total的新變項)
轉換→等級觀察值→依據剛剛的total為變數,勾選1是低分組→自訂N個等分=3,不勾選等級,會多出一個Ntotal變項,到變數檢視裡面改一下成為極端組別,在”值”那裏設定數值註解,1=低分組,2=中間組,3=高分組
編輯→選項→一般裡面,把顯示標記改為顯示名稱
選只做高分組:
資料→選擇觀察值→如果滿足設定條件→點選極端組別 = 3(資料檢視裡面就會有好多題先打斜線不列入計算)
再
分析→敘述統計→次數分配表→選十題目→確定次數分配,計算出1有幾個,佔總人數多少,就是高分組的答對率
算出來第一題全部都答對
列在表11-7 某教師自編測驗各題目
把每題的1有多少百分比填入高分組百分比
只做低分組:
資料→選擇觀察值→如果滿足設定條件→點選極端組別 = 1
分析→敘述統計→次數分配表→選十題目→次數分配,計算出1有幾個,佔總人數多少,就是高分組的答對率
算出來第一題全部都答對
把(高分組百分比-低分組百分比)/2,就是難度
分割檔案:只需要做一次
資料→分割檔案→依群組組織輸出→選極端組別過來
敘述統計→選時題,就會有看到每題的低分組看百分比,再來是中間組(不用看),高分組比分比
作業二
第四頁的建議,前面兩點都是找文即可,第三點開始要自己寫,第四點可以看第三點哪裡有錯,所以如果你是研究者會怎麼樣
作業評論寫的
一、 測量什麼p92有答案,分四大量表,有幾個類別,各幾題
二、 分數代表
三、 名詞定義
要配合你要測的哪種項目,定義一種即可,同時要跟研究目的相同,例如題目講的是服務學習,設計的題目就不要寫個人、學校、社會類別,如果答題分數最高是學校,是否代表影響利社會行為是學校影響最大而非服務學習。這樣可能做出來不符合研究目的,但其實不是沒符合目的,而是題目放的
名詞定義裡面不能再放名詞,p9公共事務態度、社會關懷…..應另外定義,並沒有解釋清楚
P86他採用的田納西自我概念量表有八個項目,在p87,可以選擇局部,但是要符合你的題目是否適用,適用的都要放
重測信度會隨著時間的長短而影響,要寫出重測信度間隔的時間
沒有錯,值得注意重測信度要寫範圍,如果是折半信度,也要交代是怎麼折半的
小數點最好是取兩位,至少要統一
引用別人的工具還是要授權,至少要寫個mail請求修改引用,並且附在論文後面
P87人際關係量表用了大學生,但是你要檢核信度和效度,或者有文獻說明為何如果用大學生都只有.53~.69,那用到高中生,至少要有Cronbach a分數至少要0.7才好,而且題數已經那麼多還只有0.53,題數變少了信度只會更低
如果各方量表題數不同,但是你去算總分,然後說這個影響最大是不行的,最好題數相同,四點五點量表也要分開。最好使用標準分數、轉換過的分數才有意義
如果性別也是重要考量,預試和真正失測要寫出性別比,預試樣本的代表性很重要
做預試就是要作項目分析好用來刪題,裡面沒刪題僅給信度係數
P95概念不同不要跑總量信度所以.043根本不用放,可以跑個項目的總量表,如果明明看起來題目跟主題應該要很有關聯,可是跑出來0.4左右,代表可能要重跑一次,或者哪個環節有問題
--
研究工具問卷應有的品質
1. 體貼受試者;
答案不要在最後一面讓大家拼命翻來翻去
題幹不要跨頁
五點量表每頁都有非常同意、同意....的表頭
如果題目內容多可以送個XG記憶卡提高填答意願
不要讓受試者還要幫你買郵票
2. 專業性
排版專業
不要錯字
3. 題目清晰易懂
不要出看不懂得名詞
題目不要過長
紙的磅數如果雙面列印不要太輕,文字不要透過去
45
信度效度
6. 妥適的題目排列
從簡單到困難
年齡或地區有一定邏輯(小到大或者大到小、近到遠遠到近)
題目相近的要放同一個區塊
哪裡可以找到研究工具
獲得已出版研究工具之相關資訊
Mental Measurements Yearbook at
http://www.unl.edu/buros/
ETS Test Collection at
http://www.ets.org/test_link/about/
心理出版社 at http://www.psy.com.tw
測驗出版商之目錄
專業期刊
測量之教科書
專業團體
http://www.ets.org/
檢索工具是否已經有人發展了?
分量表是scores
然後有評論者詳細描述(光是評論就要花錢買)
在研究背景上也可以做信度效度,嚴格的說應該要計算,可以用重測的方式來檢驗,但是最好是在前面讓受試者感受、產生對這個測驗的重要,才不會想要亂填,預防比較重要,或者在其他方面增加他們的填答意願,例如送小禮物(我覺得星巴克的飲料卡之類的不錯)
描述統計跑標準分數、某組平均數標準差中數眾數
兩位評分者間的評分者信度
多位評分者
重測信度
內部一致性
折半基數或者偶數、前半或後半
項目分析
極端組比較
小樣本分析
百多之多少較高分低分組
在某些標準下要刪除那些題目
與題目總分相關
自變項總共__個,包括性別年齡婚姻....
依變項為XXX和XXXX和XXX
題目1.
若利用極端組檢驗法(取極端的三分之一)並以臨界比大於等於5,做為選題之標準,則鑑別度比較差應刪除的題目是_____
題目2.
若利用題目總分相關法,並以相關係數大於等於0.5作為選題標準,則應考慮刪除的題目是____
題目3.
給一個題目,教學前後看成效,請算出
自我效能前測總分第一名___第二名____第三名
自我效能前測Z分數第一名___第二名____第三名
自我效能前測T分數第一名___第二名____第三名
並且計算描述統計四捨五入後填表
因素分析
斯皮爾曼發明, Cattell發揚光大
因素分析法有分兩種
探索性因素分析 (exploratory factor analysis, EFA)
驗證性因素分析 (confirmatory factory analysis, CFA)
因素分析的步驟
一、確認能不能用因素分析
因素分析是希望得到題目和題目之間相關高不高來看,如果題目之間相關都很高,它們基本上都只有一個背後因素,如果都很低代表大家因素都不同,那也不用抽了,期待看到有高有低會比較理想
淨相關是指單純自己那一題,排除掉其他題目(例如有三題,我想知道第一題的淨相關,代表第一題和第二題的相關,扣除掉第一和第二第三題共同的相關...可以用交集聯集概念來看)
反映像相關取絕對值就是淨相關,如果跑出來因素分析中的淨相關很大很大,那應該放棄使用因素分析
那麼就可以用
Bartlett的球形考驗 (test of sphericity
如果它的數據大而0則代表它可以用來做因素分析,如果不顯著的話也可以不用跑因素分析
Kaiser的抽樣適切性指數 (Kaiser-Meyer-Olkin measure of sampling adequacy; 簡稱 KMO 或 MSA)
如果十個題目每題之間的相關都很高,代表背後的因素很高,它是把所有兩兩的相關加起來,除以每一個的淨相關,希望越大越好,越適合進行進行因素分析,KMO或MSA指標0.7以上代表它可以跑因素分析
1. 因素分析條件:
並不是每個量化都可以跑因素分析,如果是名義,次數都不能跑
可以跑因素分析依定要比例或者連續變項,要是隨機並且樣本夠大(至少100,200,或者最長的分量表題數乘以5、10....至少200分會比較穩定)
二、決定抽幾個因素
抽取的方法
因素抽取的方法
1. 主成份分析法 (principal component analysis):以變異數分析為導向,選擇一組彼此獨立的成分,以簡化原來的資料關係,並儘可能解釋變項原來之變異量
2. 主軸因素法 (principal axis factoring):以共變數分析為導向,目的在藉由變項間的內部相關,找出並解釋共同變異量,以反映變項間潛在的基本結構或因素,以解釋變項間之相關
因素個數的決定
1.可以從特徵值 (eigenva1ue)判斷:特徵值代某一因素可解釋的總變異量,特徵值越大,代表該因素的解釋力越強。特徵值需大於1,才可被視為一個因素。低於1的特徵值,代表該因素的變異數少於單一變項的變異數1,無法以因素的形式存在。
2. Cattell’s的檢定是由圖形來判斷,所以稱Cattell’s陡坡檢定 (scree test):以繪圖方式檢定保留幾個因素的方法。其判斷標準是找出特徵值突然驟降之轉折彎角,在該彎角以上的幾個特徵值就是可保留下來的因數個數
殘差相關係數 (residual correlation coefficients):由共同因素所求得的變項與變項間之再製相關係數(reproduced correlation coefficients) 與原來變項間的相關係數之差為殘差相關係數,殘差相關係數愈小,表示因數分析愈成功
Y軸是特徵質,X軸是因素個數,畫出來之後看從很陡變成很緩的轉折點是在哪裡,對應出來是幾個個數就是我們要保留的因素個數
三、經過轉軸確認
是經過三角函數來計算,以直交轉軸(確定因素之間是互斥的、沒有關聯的),或者斜交轉軸(因素之間是有相關的)
四、確認之後命名,因素的命名需要一些創意和對內含的了解來扣住構念
SPSS跑因素分析:
分析
微度縮減
因子
選十個題目
萃取
主軸因子
陡坡圖要打勾
選轉軸法
斜交prom......
依據因素負荷量排序
隱藏較小的
絕對值低於0.3
確定
看報表
因素分析
要抽出題目背後共同的結構,找到彼此之間的相關,如果題目都不一樣,就會抽出好多好多因素
條件:一定要是連續變相而且符合線性
用兩種方式來檢驗是否適合用因素分析:
1. 使用巴特雷的球形考驗test of sphericity,看看有沒有顯著地高於0才可以做後續的因素分析
2. 或者使用凱瑟的抽樣適切性指數KMO如果背後有共同結構,會在0~1之間,數字越大越適合進行因素分析。0.9以上是極適合,08以上是適合,0.7以上是尚可,0.6是勉強,0.5是不適合,0.5以下:極不適合
抽因數(用何種方法、抽幾個)
1. 主成分分析法看是否能反映同一個因素,希望能解釋來的變異量
2. 主軸因素法找出內部的相關來解釋共同變異的情形
特徵值:代表此一因素可以解釋幾道題目可以反映的變異量,所以至少要大於一,至少能解釋一個題目(如果連解釋一個題目都達不到,那也不用)
Cattell’s 陡坡圖
是找到因數的個數為X軸,Y軸為特徵質,假設有十個題目,第一個因素可以解釋四個題目,特徵質是4,第二個因素的特徵質是3….把線段連起來之後就可以判斷幾個因素個數是合理的,由陡變緩的轉折就是應該保留下來的因素個數
如果轉折遇到1以下的請找前一個,至少要大於1
檢驗陡坡圖把幾個因素帶入特徵質試試看
經過轉軸可以確立如果因素相關的數值過近,經過直角轉軸(或斜交)後
如果你的論文中兩個因素完全沒有關係就用直角轉軸,如果兩個因素有關係就用斜交轉軸
可以選在第一個因素中有哪些題目,排序多到少,可以選擇sorted by size(因因素負荷量排序),這樣比較方便看由最多影響的和最少影響的
還有可以點選隱藏較少的係數0.3左右以下小於1的就不會顯示了
題號打在第一格,題目打在標記
先選一下選項→輸出→輸出標記標籤頁→名稱與標記,確定
分析→維度縮減→選題目過去→(不要放背景變向進來,只要找試題內容)
第一個步驟描述性統計→勾選係數(會有第一題和第一題的兩兩相關、第一題和第二題的兩兩相關,看有幾題就有幾個)
顯著水準則是第一題和第一題是否顯著、第一題和第二題的是否顯著……
KMO與Batterlett的球形檢定
殘差相關矩陣式要勾選重製的(較困難老師不教)
描述性統計量也要勾選第一個選項才會有描述統計平均數和標準差與個數(可以看出排除幾個觀察值,在選項裡面有)
第二個步驟萃取,使用主成分分析法的話不太好,在七中當中應該使用主軸因子會比較好(邱浩振老師裡面的書都有寫錯喔,應該都用主軸因子法)
要抽取幾個因素,可以根據特徵質並大於1,另外可以透過勾選陡坡圖來看。如果自己有確定幾個因子可以直接寫數字(薪資對加班費、導師費的滿意度)
再來第三個要寫轉軸法:如果假設因子之間是沒有相關的,有相關的請選擇最大變異法是正交轉軸,promax是斜交轉軸法,按下繼續
請勾選根據因素負荷排序、隱藏較小,絕對值低於3的(就隱藏不要出現)
本來有十題,勾了因子分析裡面的因素存成變數,那按下確定之後可能就會增加變成13個變項。當然也可以看出男生女生不同,可以把性別放入選擇變數欄位,就會分別幫你跑
接下來看KMO與Battelett先看顯著性,是有顯著的,代表整體而言這些試題有顯著的相關性質
Kaiser取樣適切0.879代表適合做因素分析
接著看報表反映像矩陣取樣適切性輛數MSA看報表上斜對角的數字(右上角有個小a的數字)(也是0.7以上就可以因素分析),如果有低於0.7,那麼再做一次,不要把這題丟進去跑
共同性報表請看萃取的,代表把這題當依變相,其他題是自變項去做多元回歸來預測,去找出這一題和其他題群的相關,稱為多元相關R,一個題目和另一個題目的相關叫簡單相關r,多元相關的平方就是決定係數,就看第一題和其他題共同的部分有多少?共同性越大代表重要性越高,適合因素分析
解說總變異量報表裡面,有十個題目應該會有十個因子,看總數那攔,第一個因素可以解釋幾題,等一下輸入幾個因子就由此判斷
看陡坡圖中油斗變緩是介於兩個或三個因素,搭配剛剛的特徵質是否小於1,小於1就不要,來決定到底有輸入幾個因子
因此因素矩陣就從10個變成2個了
因素負荷量是在因子矩陣的報表,如果有空白代表小於0.3(剛剛自己的設定),如果某個題目跟因素1和2都很接近,判斷會有困難,這時候就要做轉軸
轉軸之後會有兩個矩陣pattern matri樣式矩陣(是利用淨回歸和淨相關,看的是相對重要性)和 structure matrix結構矩陣(因素1裡有哪些試題、因素2…)
基本上先看結構矩陣,如果仍難判別,在看樣式矩陣
結構矩陣中排列過後假設因素1的數字都比因素2大,前面六題都是,因素2比因素1大的時候,則下半部,就可以畫一條線切開,因素1有哪些題目,因素2有那些數字
矩陣式樣式可以看要保留幾題
只要選擇斜交轉軸,就會算出兩者相關,呈現在因子相關矩陣,
最後的因子命名,可以看結構矩陣,會發現因子1的題目假設都是正向的,因子2的題目假設都是負向的,依據文獻,這時候可以將這兩個因子命名為正向的....負向的....(都要依據文獻與對論文的了解來命名)
重測信度、輻和信度、區辨效度(又有分為同特質相同方法和不同特質不同方法)
應該要A>B>C>D
生涯自我效能量表有分為
信心強度
難度知覺
推論性
那麼個別(信心強度)和問卷總分的相關要很高,但是個別層面(信心強度、難度知覺、推論性)之間不能相關很高,相關很高代表沒有區別了
11.26
做問卷的流程:
試題給專家審閱
修正完給未來要施測的母群體做預試
此時項目分析會很重要,它能讓你檢視你的題目好不好
項目分析很重要
項目分析分為質與量化,質的部分是要先給專家檢視,再來要給未來施測的母群體做預試,如果你本來的樣本就很小只有一個班或者少數人,此時可以換成類似各種條件(學區、年齡、特質)的群體來施測
預試施測一定要自己來,這樣受試者如果有反應你可以馬上收到意見修正,叫別人幫你做也許不會反應給你
好的研究工具標準差要大
預試可以為構念中最長題目的五倍(我的指導教授是說100份),如果後面有要做高分組低分組,每組至少要有30人,如果後面想做因素分析,大約至少要200分,如果你的樣本沒有超過200個根本不用做因素分析了,總人數沒有到90個人,這樣高低組根本沒有30個也不用做極端值t考驗了
遺漏質會產生可能有兩種情況,第一個是題目太難、描述太難導致受試者看不懂不之如何回答,第二種是太隱私使受試者不願意回答,此時就要修改題目到可以容易閱讀或者不那麼敏銳地問到想問的
如果你要了解的群體是常態分佈的,集中量數要在中間,如果是有某些問題的議題或族群(例如要做行動研究),他們的集中量數是要偏低的才算合理,變異量數會是小的(大家都答錯都不好)
如果你預試有50題很多,最後希望有25題,這時候會砍掉的題目很多,標準差的範圍就可以設小一點,超出太多的就砍,相反的如果你只能踢掉三題,那麼即使跟大家差很多,還是要留下來
檢查的方式,使用次數分配表裡面的描述統計來看遺漏值(偏態和峰度要自己打勾),選好所有的題目進框框,看第一題的框框,遺漏值=5代表有第一題五個人漏答了,請整理每個題目是甚麼,漏答率有多少
要整理成表格可以在輸出的表格點兩下,藉由右鍵→樞軸→轉置,就會左邊列是題目,右邊是,偏態的標準誤、峰度、峰度的標準誤都可以可以刪除
遺漏值有些問卷有提供非常滿意、滿意、不滿意、非常不滿意、無法作答,此時無法作答跟沒答都列為遺漏值
(會有無法作答是因為這個問卷的特性,並不是每個都問卷都需要)
通常遺漏值可以用個位數的最大值例如9,通常一開始就要設定遺漏值是多少(例如年齡,就寫99是遺漏值)
系統遺漏跟無法作答會歸類在一起
用item analysis這個檔案,以後要用預試就可以用這個檔案的格式
改一下編輯→選項→輸出標記改成「值與標記」可以看到每個代表什麼(1=非常同意,2=同意.....)
kelley統計學者提出是用前27%和最後27%作為界線是最有鑑別度,首先找總分多少,再來用百分位數用第73百分位數(PR=73),只要大於等於PR73的都叫做高分組,再找到PR只要低於27的都叫做低分組
如果兩組的平均數差異比較,用獨立樣本T考驗,如果有前後測但是是同一組,用相依樣本T考驗
也就是假設高分組的平均和低分組的平均,應該要高分組的平均要顯著高於低分組的平均
如何找出適合的好試題保留?
小樣本分析是用來考驗兩組極端組的得分平均,步驟如下:
1. 計算每題的總分
2. 找出高低分組
3. 使用獨立樣本T考驗(如果不顯著就可以剔除)
有顯著考驗才算好試題
4. 判斷
除了看是否簡述外,大樣本時可以找critical ratio臨界比,把T值取絕對值,如果是大於三的才可以算是好試題
用compute
選百分位數
轉換
作法:
1. 轉換→計算變數→統計→mean(用mean而不是sum這樣會幫妳寫回1~4選項,而不是平均分數,會幫你踢掉遺漏質),新增一個total
2. 分析→敘述統計→次數分配表,選剛剛新增的total→統計量→百分位數=27和73
3. 轉換→重新編碼成不同變數→選total,名稱打上組別,標記為極端組分組,按下變更,再按新質與舊質,選範圍,值到highest,2.9904.選新值為2(高分組),再設低分組
在按確定
新的組別中有
不想看到小數點可以到變數檢視裡面把小數點的位數改為0,把值得部分寫好1=高分組
平均數的差異除以標準誤就是T值的概念
分析→獨立樣本T考驗
獨立樣本T考驗作法:
獨立樣本T考驗→選好所有題目過去,分組變數選極端組分組,使用指定的數值裡放1和2,放相反也沒關係,只是T值的正負問題
定義組別1放2(高分組),組別2放1(低分組),並不影響顯著差異,只是看高分組減低分組還是相反
每組的人數不太相同是正確的
看第二個表格獨立樣本檢定,看到t那欄,顯著性是p值,如果樣本是隨機抽取而來的,第二個變異數要同質,第三個要常態分配,這樣才能用t檢定
因此t值有兩個是因為,公式幫你校正
如果高分組都是3.59分,低分組又有1分又有3分
如果Levene的顯著性p值是大於0.05
以第一題為例,
F檢定 顯著性 t 自由度 顯著性(雙尾)
.238 .627 14.655(=14.66) .000
14.683
當F檢定旁的顯著性如果是大於0.05要看上面那個t的數字
如果是小於等於0.05要看下面那個t的數字
t要寫作 14.66***
因為顯著性雙尾如果小於0.5是*,小於0.1是**,小於0.01(.000代表0.0000000XXX)是***
最後要標回去14.66***
同質性檢驗要把態度構念的項目加總和全部題目的相關、行為構念的項目加總和全部題目的相關(都要高才對),不要把全部題目跟總分直接相關,除非他們構念完全相同
題目和總分的相關:
分析→尺度→信度分析→選50題。統計量那裏勾選刪除項目後之量尺摘要(出來的報表代表刪掉自己這題之後,其他題目和總分的平均數或相關),這樣的相關比自己和50題的相關更嚴謹,這是校正後的題目總分相關(扣掉自己了)
.944
考題舉例:
如果老師的題目標準是0.4,修正的項目總相關是0.4以下的題號就要刪除了
sort描述性統計量,可以算出Z分數
因素負荷量:
分析→維度縮減→因素→移入題目→萃取→主成分→固定因子數目:1,確定,報表請拉到最後,看成分矩陣a,填回因素負荷
因素分析法最起碼要0.3
刪題標準可以用:
用遺漏值5%:
平均數的上下範圍:敘述統計選total選平均數和標準差,用一個標準差之內2.71+0.47~2.71-0.47,=2.24~3.18,之外的叫做不好
標準差:越大越好,所以標準為0.83,小於等於0.83的要去掉(可以刪掉十個)
偏態希望可以常態分配,所以偏態係數絕對值大於1的不能要(都可以要)
極端組t檢定(臨界比)若用3(看絕對值)只能刪掉幾題,甚至可以
相關:0.3以下的刪除(含0.3)
所以每題被圈了幾次,圈很多就很不好,老師會問如果只能刪1題,刪第5題會刪掉哪些題目
--
12.11
老師說測量研究第三個作業,如果你的論文用不到這樣的測驗工具,那可以兩人一組,如果論文題目也訂了
難度分析,難度的數字越大代表越簡單,最高是1,也就是100% ,有兩種算法,第一種是通過的人佔全體多少比率,第二種算法是高分組裡面的通過人數除以高分組的人數加上低分組通過人除以低分組總人數再除以2(高分組的通過率+低分組的通過率再除以2)
鑑別度是高分組的答對率減低分組的答對率
先算總分,算出PR然後算出大於27
通過率:
1. 高分組低分組,選擇高分組算出答對的,用次數分配那些人答對,計算有芬的是那些人,最後相加除二,鑑別度則是兩個相減
2. 等級觀察值,選擇某一組看答對率,用分割檔案也可以,每個組別都幫你做一次
檔案在Item analysis壓縮檔中 diffically這個SPSS檔案:有十個題目,答對是1 ,如果你的題目是四個選項的可以用轉換,答對的給1,答錯的給0
要先算總分:轉換→計算變數→自己寫目標變數為total統計→點兩下sum 自己key v1 to v2 。(設立一個total的新變項)
轉換→等級觀察值→依據剛剛的total為變數,勾選1是低分組→自訂N個等分=3,不勾選等級,會多出一個Ntotal變項,到變數檢視裡面改一下成為極端組別,在”值”那裏設定數值註解,1=低分組,2=中間組,3=高分組
編輯→選項→一般裡面,把顯示標記改為顯示名稱
選只做高分組:
資料→選擇觀察值→如果滿足設定條件→點選極端組別 = 3(資料檢視裡面就會有好多題先打斜線不列入計算)
再
分析→敘述統計→次數分配表→選十題目→確定次數分配,計算出1有幾個,佔總人數多少,就是高分組的答對率
算出來第一題全部都答對
列在表11-7 某教師自編測驗各題目
把每題的1有多少百分比填入高分組百分比
只做低分組:
資料→選擇觀察值→如果滿足設定條件→點選極端組別 = 1
分析→敘述統計→次數分配表→選十題目→次數分配,計算出1有幾個,佔總人數多少,就是高分組的答對率
算出來第一題全部都答對
把(高分組百分比-低分組百分比)/2,就是難度
分割檔案:只需要做一次
資料→分割檔案→依群組組織輸出→選極端組別過來
敘述統計→選時題,就會有看到每題的低分組看百分比,再來是中間組(不用看),高分組比分比
作業二
第四頁的建議,前面兩點都是找文即可,第三點開始要自己寫,第四點可以看第三點哪裡有錯,所以如果你是研究者會怎麼樣
作業評論寫的
一、 測量什麼p92有答案,分四大量表,有幾個類別,各幾題
二、 分數代表
三、 名詞定義
要配合你要測的哪種項目,定義一種即可,同時要跟研究目的相同,例如題目講的是服務學習,設計的題目就不要寫個人、學校、社會類別,如果答題分數最高是學校,是否代表影響利社會行為是學校影響最大而非服務學習。這樣可能做出來不符合研究目的,但其實不是沒符合目的,而是題目放的
名詞定義裡面不能再放名詞,p9公共事務態度、社會關懷…..應另外定義,並沒有解釋清楚
P86他採用的田納西自我概念量表有八個項目,在p87,可以選擇局部,但是要符合你的題目是否適用,適用的都要放
重測信度會隨著時間的長短而影響,要寫出重測信度間隔的時間
沒有錯,值得注意重測信度要寫範圍,如果是折半信度,也要交代是怎麼折半的
小數點最好是取兩位,至少要統一
引用別人的工具還是要授權,至少要寫個mail請求修改引用,並且附在論文後面
P87人際關係量表用了大學生,但是你要檢核信度和效度,或者有文獻說明為何如果用大學生都只有.53~.69,那用到高中生,至少要有Cronbach a分數至少要0.7才好,而且題數已經那麼多還只有0.53,題數變少了信度只會更低
如果各方量表題數不同,但是你去算總分,然後說這個影響最大是不行的,最好題數相同,四點五點量表也要分開。最好使用標準分數、轉換過的分數才有意義
如果性別也是重要考量,預試和真正失測要寫出性別比,預試樣本的代表性很重要
做預試就是要作項目分析好用來刪題,裡面沒刪題僅給信度係數
P95概念不同不要跑總量信度所以.043根本不用放,可以跑個項目的總量表,如果明明看起來題目跟主題應該要很有關聯,可是跑出來0.4左右,代表可能要重跑一次,或者哪個環節有問題
--
研究工具問卷應有的品質
1. 體貼受試者;
答案不要在最後一面讓大家拼命翻來翻去
題幹不要跨頁
五點量表每頁都有非常同意、同意....的表頭
如果題目內容多可以送個XG記憶卡提高填答意願
不要讓受試者還要幫你買郵票
2. 專業性
排版專業
不要錯字
3. 題目清晰易懂
不要出看不懂得名詞
題目不要過長
紙的磅數如果雙面列印不要太輕,文字不要透過去
45
信度效度
6. 妥適的題目排列
從簡單到困難
年齡或地區有一定邏輯(小到大或者大到小、近到遠遠到近)
題目相近的要放同一個區塊
哪裡可以找到研究工具
獲得已出版研究工具之相關資訊
Mental Measurements Yearbook at
http://www.unl.edu/buros/
ETS Test Collection at
http://www.ets.org/test_link/about/
心理出版社 at http://www.psy.com.tw
測驗出版商之目錄
專業期刊
測量之教科書
專業團體
http://www.ets.org/
檢索工具是否已經有人發展了?
分量表是scores
然後有評論者詳細描述(光是評論就要花錢買)
在研究背景上也可以做信度效度,嚴格的說應該要計算,可以用重測的方式來檢驗,但是最好是在前面讓受試者感受、產生對這個測驗的重要,才不會想要亂填,預防比較重要,或者在其他方面增加他們的填答意願,例如送小禮物(我覺得星巴克的飲料卡之類的不錯)
描述統計跑標準分數、某組平均數標準差中數眾數
兩位評分者間的評分者信度
多位評分者
重測信度
內部一致性
折半基數或者偶數、前半或後半
項目分析
極端組比較
小樣本分析
百多之多少較高分低分組
在某些標準下要刪除那些題目
與題目總分相關
自變項總共__個,包括性別年齡婚姻....
依變項為XXX和XXXX和XXX
題目1.
若利用極端組檢驗法(取極端的三分之一)並以臨界比大於等於5,做為選題之標準,則鑑別度比較差應刪除的題目是_____
題目2.
若利用題目總分相關法,並以相關係數大於等於0.5作為選題標準,則應考慮刪除的題目是____
題目3.
給一個題目,教學前後看成效,請算出
自我效能前測總分第一名___第二名____第三名
自我效能前測Z分數第一名___第二名____第三名
自我效能前測T分數第一名___第二名____第三名
並且計算描述統計四捨五入後填表
因素分析
斯皮爾曼發明, Cattell發揚光大
因素分析法有分兩種
探索性因素分析 (exploratory factor analysis, EFA)
驗證性因素分析 (confirmatory factory analysis, CFA)
因素分析的步驟
一、確認能不能用因素分析
因素分析是希望得到題目和題目之間相關高不高來看,如果題目之間相關都很高,它們基本上都只有一個背後因素,如果都很低代表大家因素都不同,那也不用抽了,期待看到有高有低會比較理想
淨相關是指單純自己那一題,排除掉其他題目(例如有三題,我想知道第一題的淨相關,代表第一題和第二題的相關,扣除掉第一和第二第三題共同的相關...可以用交集聯集概念來看)
反映像相關取絕對值就是淨相關,如果跑出來因素分析中的淨相關很大很大,那應該放棄使用因素分析
那麼就可以用
Bartlett的球形考驗 (test of sphericity
如果它的數據大而0則代表它可以用來做因素分析,如果不顯著的話也可以不用跑因素分析
Kaiser的抽樣適切性指數 (Kaiser-Meyer-Olkin measure of sampling adequacy; 簡稱 KMO 或 MSA)
如果十個題目每題之間的相關都很高,代表背後的因素很高,它是把所有兩兩的相關加起來,除以每一個的淨相關,希望越大越好,越適合進行進行因素分析,KMO或MSA指標0.7以上代表它可以跑因素分析
1. 因素分析條件:
並不是每個量化都可以跑因素分析,如果是名義,次數都不能跑
可以跑因素分析依定要比例或者連續變項,要是隨機並且樣本夠大(至少100,200,或者最長的分量表題數乘以5、10....至少200分會比較穩定)
二、決定抽幾個因素
抽取的方法
因素抽取的方法
1. 主成份分析法 (principal component analysis):以變異數分析為導向,選擇一組彼此獨立的成分,以簡化原來的資料關係,並儘可能解釋變項原來之變異量
2. 主軸因素法 (principal axis factoring):以共變數分析為導向,目的在藉由變項間的內部相關,找出並解釋共同變異量,以反映變項間潛在的基本結構或因素,以解釋變項間之相關
因素個數的決定
1.可以從特徵值 (eigenva1ue)判斷:特徵值代某一因素可解釋的總變異量,特徵值越大,代表該因素的解釋力越強。特徵值需大於1,才可被視為一個因素。低於1的特徵值,代表該因素的變異數少於單一變項的變異數1,無法以因素的形式存在。
2. Cattell’s的檢定是由圖形來判斷,所以稱Cattell’s陡坡檢定 (scree test):以繪圖方式檢定保留幾個因素的方法。其判斷標準是找出特徵值突然驟降之轉折彎角,在該彎角以上的幾個特徵值就是可保留下來的因數個數
殘差相關係數 (residual correlation coefficients):由共同因素所求得的變項與變項間之再製相關係數(reproduced correlation coefficients) 與原來變項間的相關係數之差為殘差相關係數,殘差相關係數愈小,表示因數分析愈成功
Y軸是特徵質,X軸是因素個數,畫出來之後看從很陡變成很緩的轉折點是在哪裡,對應出來是幾個個數就是我們要保留的因素個數
三、經過轉軸確認
是經過三角函數來計算,以直交轉軸(確定因素之間是互斥的、沒有關聯的),或者斜交轉軸(因素之間是有相關的)
四、確認之後命名,因素的命名需要一些創意和對內含的了解來扣住構念
SPSS跑因素分析:
分析
微度縮減
因子
選十個題目
萃取
主軸因子
陡坡圖要打勾
選轉軸法
斜交prom......
依據因素負荷量排序
隱藏較小的
絕對值低於0.3
確定
看報表
因素分析
要抽出題目背後共同的結構,找到彼此之間的相關,如果題目都不一樣,就會抽出好多好多因素
條件:一定要是連續變相而且符合線性
用兩種方式來檢驗是否適合用因素分析:
1. 使用巴特雷的球形考驗test of sphericity,看看有沒有顯著地高於0才可以做後續的因素分析
2. 或者使用凱瑟的抽樣適切性指數KMO如果背後有共同結構,會在0~1之間,數字越大越適合進行因素分析。0.9以上是極適合,08以上是適合,0.7以上是尚可,0.6是勉強,0.5是不適合,0.5以下:極不適合
抽因數(用何種方法、抽幾個)
1. 主成分分析法看是否能反映同一個因素,希望能解釋來的變異量
2. 主軸因素法找出內部的相關來解釋共同變異的情形
特徵值:代表此一因素可以解釋幾道題目可以反映的變異量,所以至少要大於一,至少能解釋一個題目(如果連解釋一個題目都達不到,那也不用)
Cattell’s 陡坡圖
是找到因數的個數為X軸,Y軸為特徵質,假設有十個題目,第一個因素可以解釋四個題目,特徵質是4,第二個因素的特徵質是3….把線段連起來之後就可以判斷幾個因素個數是合理的,由陡變緩的轉折就是應該保留下來的因素個數
如果轉折遇到1以下的請找前一個,至少要大於1
檢驗陡坡圖把幾個因素帶入特徵質試試看
經過轉軸可以確立如果因素相關的數值過近,經過直角轉軸(或斜交)後
如果你的論文中兩個因素完全沒有關係就用直角轉軸,如果兩個因素有關係就用斜交轉軸
可以選在第一個因素中有哪些題目,排序多到少,可以選擇sorted by size(因因素負荷量排序),這樣比較方便看由最多影響的和最少影響的
還有可以點選隱藏較少的係數0.3左右以下小於1的就不會顯示了
題號打在第一格,題目打在標記
先選一下選項→輸出→輸出標記標籤頁→名稱與標記,確定
分析→維度縮減→選題目過去→(不要放背景變向進來,只要找試題內容)
第一個步驟描述性統計→勾選係數(會有第一題和第一題的兩兩相關、第一題和第二題的兩兩相關,看有幾題就有幾個)
顯著水準則是第一題和第一題是否顯著、第一題和第二題的是否顯著……
KMO與Batterlett的球形檢定
殘差相關矩陣式要勾選重製的(較困難老師不教)
描述性統計量也要勾選第一個選項才會有描述統計平均數和標準差與個數(可以看出排除幾個觀察值,在選項裡面有)
第二個步驟萃取,使用主成分分析法的話不太好,在七中當中應該使用主軸因子會比較好(邱浩振老師裡面的書都有寫錯喔,應該都用主軸因子法)
要抽取幾個因素,可以根據特徵質並大於1,另外可以透過勾選陡坡圖來看。如果自己有確定幾個因子可以直接寫數字(薪資對加班費、導師費的滿意度)
再來第三個要寫轉軸法:如果假設因子之間是沒有相關的,有相關的請選擇最大變異法是正交轉軸,promax是斜交轉軸法,按下繼續
請勾選根據因素負荷排序、隱藏較小,絕對值低於3的(就隱藏不要出現)
本來有十題,勾了因子分析裡面的因素存成變數,那按下確定之後可能就會增加變成13個變項。當然也可以看出男生女生不同,可以把性別放入選擇變數欄位,就會分別幫你跑
接下來看KMO與Battelett先看顯著性,是有顯著的,代表整體而言這些試題有顯著的相關性質
Kaiser取樣適切0.879代表適合做因素分析
接著看報表反映像矩陣取樣適切性輛數MSA看報表上斜對角的數字(右上角有個小a的數字)(也是0.7以上就可以因素分析),如果有低於0.7,那麼再做一次,不要把這題丟進去跑
共同性報表請看萃取的,代表把這題當依變相,其他題是自變項去做多元回歸來預測,去找出這一題和其他題群的相關,稱為多元相關R,一個題目和另一個題目的相關叫簡單相關r,多元相關的平方就是決定係數,就看第一題和其他題共同的部分有多少?共同性越大代表重要性越高,適合因素分析
解說總變異量報表裡面,有十個題目應該會有十個因子,看總數那攔,第一個因素可以解釋幾題,等一下輸入幾個因子就由此判斷
看陡坡圖中油斗變緩是介於兩個或三個因素,搭配剛剛的特徵質是否小於1,小於1就不要,來決定到底有輸入幾個因子
因此因素矩陣就從10個變成2個了
因素負荷量是在因子矩陣的報表,如果有空白代表小於0.3(剛剛自己的設定),如果某個題目跟因素1和2都很接近,判斷會有困難,這時候就要做轉軸
轉軸之後會有兩個矩陣pattern matri樣式矩陣(是利用淨回歸和淨相關,看的是相對重要性)和 structure matrix結構矩陣(因素1裡有哪些試題、因素2…)
基本上先看結構矩陣,如果仍難判別,在看樣式矩陣
結構矩陣中排列過後假設因素1的數字都比因素2大,前面六題都是,因素2比因素1大的時候,則下半部,就可以畫一條線切開,因素1有哪些題目,因素2有那些數字
矩陣式樣式可以看要保留幾題
只要選擇斜交轉軸,就會算出兩者相關,呈現在因子相關矩陣,
最後的因子命名,可以看結構矩陣,會發現因子1的題目假設都是正向的,因子2的題目假設都是負向的,依據文獻,這時候可以將這兩個因子命名為正向的....負向的....(都要依據文獻與對論文的了解來命名)
PR值(percentile ranks),是一種名次的概念,百分位數是分數的概念,是等距變項,PR值不是等距的,是名次概念變數檢視等於是右鍵內容,把每個行與列的特性給定義,是文字還是數字
次數分配表,來源變項清單,可以按下ctrl來選個別,總和是把某個變項的受試者全部加起來
變異量數有包含標準差、變異數、最大值最小值,全距在框框裡稱為叫範圍
分配看偏態係數(正偏或者)峰度是高陜或者低闊峰,四分位數會出現第25%的、75、50..或者可以定義百分位數第27、73的前1/3的人是要找百分位數67,後1/3是要找百分位數33
名義變項會用長條圖,每個bar中間會有空間,智商與學習成就是連續變項,建議一開始先選兩個變項,名義變項與連續變項分開跑圖形,圓餅圖是適合名義變項
依觀察值遞增或者遞減是從人數最多或者最少的開始排,如果要分組(男生女生)要改用別的指令
眾數可以多個,50分有12個,30分也有12個
標準差的平方是變異數
偏態和峰度系數取絕對值小於等於1為常態分配,等於0剛好是常態分配,離0越遠越不是常態
C是控制組,E是實驗組,若希望輸出結果(例如1代表非常同意、2代表同意)可以到編輯,選項,執行之前把輸出標記改成名稱與標記,數值要值與標記
按下套用與確定
如果希望表格上面顯示出來1=男生,2=女生這樣的註記,記得在問券輸入編碼的時候不要使用文字C、E(控制組實驗組),記得直接用1,2來編碼,這樣才會跑出來
如果不小心已經都用文字來編碼(C=控制組),還可以用轉換→重新編碼成不同變數(不會蓋掉原本的),
(group取個新名字,要按下"變更",再按好)
論文中表格最好都是中文,不要用CE
小數點取到第二位就可以了
APA格式有些不能用SPSS跑過就好了,某些沒有線,有些有線,有自由度等值要補上、顯著的數字或者合併
如果欄和列要交換可以貼到excel(回去查方法),或者可以SPSS在輸出的框框裡點兩下編輯,在樞軸表,選樞軸,裡面選轉置,就可以X和Y軸行和列交換
Descriptives敘述性統計量(能跑Z分數)
Z分數可以算連續變項的標準分數,名義變項的標準分數不能算(例如性別沒辦法算標準差)
分析→敘述統計→描述性統計量(只能用在連續變項)→學習
成就溝選「將標準的數值變成變數」=計算Z分數,然後按下選項按鈕
在敘述統計量的視窗中會看不到名目選項(無法計算)
名目選項可以在"不同欄位"去更改
如果你要把要做同樣的步驟的資料分析,可以把語法檔存起來,可以選「貼上之後」(幫你把剛剛選擇的選擇項目重作),此時只有跑出語法視窗,還要按下執行才會跑出報表
Z分數會在資料分析視窗,不會在輸出檔,Zachievement就是Z分數
Explore是預檢資料,做資料檢查、資料預檢之用,特色是可以按照組別來(男生組自己跑,女生組自己跑以及全體一起跑),可以找偏離值(Outliers),有盒狀圖,可以做
如果要跑組別自己的資料可以把智商放第一個依變數清單,勾選統計量,裡面有信賴區間95%,M估計值比平均數中數更
能精確反映,當是用在偏離常態的狀況時,如果發現偏態並不是常態,那就看M估計值
如果假設考驗的結果是
利用統計軟體來跑就是使用P值法
H0虛無假設是偏態係數是否等於0(常態分配)
H1對立假設是偏態係數不等於0
P值法:阿法設定=.05
ANOVA=變異數分析,裡面有個F值,F值使因為就是R.A. Fisher這個人所建立的
P值是小於0.05代表落入虛無假設(常態分配圖上兩邊的虛無假設中)把p值去跟阿法值相比,P<阿法要拒絕虛無假設
p值若大於阿法值(通常設為0.05),代表在中間這塊,要接受h0,偏態係數=0,為常態
常態性檢定,顯著性=P值=0.09,P>阿法,偏態係數相當於0,為常態分配,所以接受H0,智商是呈常態分配
下午茶的故事:這幾位統計學家(英國),在喝下午茶,先倒入紅茶再放入牛奶,有位女士經過,跟他說先放牛奶再沖紅茶比較好喝,這幾位統計學家就想試驗看看,沖了20杯奶茶,讓她喝猜看看,結果20杯她只猜錯一杯,所以就是0.05....代表她是對的,仍分得出來先沖茶還是先沖奶比較好喝
summarize不教,少用
Means可以分組作統計量,可以做T考驗、變異數分析,考驗
兩個連續變項有沒有線性關係
(分析→比較平均數法→平均數)
例如想看智商在男女上有沒有差別,就把智商放第一個框框,第二個框框放組別,裡面勾選Anova表格會做變異數分析
,如果智商和組別都是連續變項才可以勾線性關係的檢定(但是兩者都不是)
Anova摘要表的平均平方和要改為平均值,F檢定請改為F值,sig.就是P值
若F值為3.209,P值為.08,控制組和實驗組是沒有差異的,雖然在報表中兩組的智商是120和111,但是其實智商差個9
是沒有差異的
H0:F=0
H1:F不等於0
如果是0.03代表控制組的智商是顯著高於實驗組的
比較兩組的時候,t平方=F,F開平方=t
因此F考驗相當於t考驗的結果
如果平均數、中位數跟M算出來四種估計值差很多,代表他不是常態分配
在50個人95%的人智商是落在114~118之間
勾選偏離值是最大個五個人、最小的五個人會去除掉,刪除
兩極端各5%觀察值平均數
考驗智商此變項是否偏離常態分配請勾選「常態機率圖附檢定」
M估計值
莖的寬度是10 wtem width 10,請莖加葉,
代表有112和113兩個智商(10X10+2,10X10+3)
盒形圖有人的得分,是盒長的1.5倍會出現圈圈,是盒長的3倍,會出現星星,代表極端值,上面標示哪一號是極端值
盒狀圖中間那條線是中位數,盒子的上端線是Q3,盒子的下端是Q1
遺漏值的處理方法
ID 變項1 變項2 變項3
1 3 ● ●
2 ● 4 5
3 5 ● 5
4 ● 3 4
1. 完全排除觀察值 會只剩下一個受試者(會大量移失受試者)
2. 成對排除法:只有被你納入分析的變項才會排除掉,我選第一個和第三個變項會有兩個受試者(選這個比較好)
3. 報表值(會把有遺漏的列出來)
信度 因為每個測驗都會有誤差值,理論上說無限次的分數誤差值總為零 信度是分數測驗結果的一致性或者穩定性,一個受試者做兩份,或是一個團體抽一些人 冷氣或者照明會是一種影響而產生的誤差,稱為系統誤差(大家一起變低分或者高分),系統性誤差不會影響信度 隨機誤差是一種個別誤差 信度係數是用相關係數r來表示 包括: 重測信度=穩定信度=再測信度(用皮爾森相關係數,時間越短相關係數越高,越相關,誤差來源為時間) 複本信度=等值係數=(兩個測驗的內容等值,同一時間去測,誤差來源為內容) 重測副本信度,結合前面兩個(等值的兩個測驗在不同時間測量同一個群體,誤差來源又有時間和內容) 內部一致性係數(只有一次失測):包含折半辦法、庫李法 在論文中 要做複本信度要講題目到底多少題,10題的題目就0.8那麼變成20題那麼信度會更高 做重測信度要講時間隔多久,因為時間會影響 要依照測驗的性質,例如人格,三個月前後施測應該相關很高 成就測驗可能變動很大,不能隔太久 折半信度會有很大的問題,50個題目如何拆成各25題有非常多個折半信度,要用哪種呢?所以不要 庫李法是適用於對錯是非、或者只有同意或者不同意(適合用於成就題目),在SPSS裡面沒有可以用阿法法 阿法法(適用於李克特五點量表) 如何用SPSS跑信度 原理: 兩個變項之相關,最好先看要看是否線性關係,用散布圖,如果是沒有線性關係的去跑皮爾森係數會等於0 變異數是算個別分數在群體中的變動情況,個別分數減掉平均數 共變數 標準化之後 -1小於等於r小於等於1 Pearson積差相關可以算 直線相關 重測信度、複本信度 內部一致性 建構效度 預測 Spearman兩個變項 肯德爾的和諧係數適用於多個評分者 重測 複本 重測複本 分析analyze→相關correlate→雙變數bivariate
老師是用alpha test retest parallel這個資料檔來跑測驗
重測信度用相關係數 pearson r
math1和math2是重測信度(同分測驗同個團體在不同時間做)
分析→雙變數點選math1和math2,勾選(pearson)相關係數
顯著性測驗就是
雙尾檢定時,阿法值為0.05/2=0.025較嚴格,如果只差一點點會落入虛無假設,又有文獻中很明確知道這個測驗一定是正相關或者負相關,可以改為單尾檢定
信度不用做單尾或者雙尾顯著
信度的寫法:
數學1和數學2的相關是0.751 r=0.751,他們的重測信度是0.751
如果改成身高和體重的相關,則p=0.000代表後面還有東西,代表p小於0.001,(SPSS只能顯示三位小數點)
相關係數的寫法:
樣本的相關r=.751
阿法=0.05
代表這兩個變項有顯著相關p小於等於阿法
虛無假設:母群體的相關是0,對立假設
p小於等於阿法要拒絕h0
p大於等於阿法要接受h0
r平方等於決定係數
第一次和第二次的重疊的部分只有49%
如果是0.751平方
SPSS跑複本信度
分析→相關→雙變數
read1a和read1b
確定
就是複本信度
=0.817
內部一致性信度分析
分析→尺度→信度分析
選擇題目1~15(題目的數值會是1和0)
模式看要折半信度或者阿法法
若有15題程式會拆成七題和八題(spearman-brown係數要選不等長的)
0.668是前八題的,
折半信度校正過後的是斯布校正公式
如果題目是16題要選等長的spearman-brown係數
15題如果要選單數題和雙數題的折半信數,就選1、3、5、7、9、11、13、15完再選2、4、6、8、10、12、14,這樣就可以跑
要跑庫李信度也是一樣不用管勾選題號順序跑阿法值就可以了
如果有勾選差機離差代表(x-x的平均)(y-y平均)總和,再除N,會出來共變數
11.13
分析→無母數分析→歷史對話紀錄(在SPSS12以後有多一層)→K個相關樣本
之後補上
重測信度、輻和信度、區辨效度(又有分為同特質相同方法和不同特質不同方法)
應該要A>B>C>D
生涯自我效能量表有分為
信心強度
難度知覺
推論性
那麼個別(信心強度)和問卷總分的相關要很高,但是個別層面(信心強度、難度知覺、推論性)之間不能相關很高,相關很高代表沒有區別了
11.26
做問卷的流程:
試題給專家審閱
修正完給未來要施測的母群體做預試
此時項目分析會很重要,它能讓你檢視你的題目好不好
項目分析很重要
項目分析分為質與量化,質的部分是要先給專家檢視,再來要給未來施測的母群體做預試,如果你本來的樣本就很小只有一個班或者少數人,此時可以換成類似各種條件(學區、年齡、特質)的群體來施測
預試施測一定要自己來,這樣受試者如果有反應你可以馬上收到意見修正,叫別人幫你做也許不會反應給你
好的研究工具標準差要大
預試可以為構念中最長題目的五倍(我的指導教授是說100份),如果後面有要做高分組低分組,每組至少要有30人,如果後面想做因素分析,大約至少要200分,如果你的樣本沒有超過200個根本不用做因素分析了,總人數沒有到90個人,這樣高低組根本沒有30個也不用做極端值t考驗了
遺漏質會產生可能有兩種情況,第一個是題目太難、描述太難導致受試者看不懂不之如何回答,第二種是太隱私使受試者不願意回答,此時就要修改題目到可以容易閱讀或者不那麼敏銳地問到想問的
如果你要了解的群體是常態分佈的,集中量數要在中間,如果是有某些問題的議題或族群(例如要做行動研究),他們的集中量數是要偏低的才算合理,變異量數會是小的(大家都答錯都不好)
如果你預試有50題很多,最後希望有25題,這時候會砍掉的題目很多,標準差的範圍就可以設小一點,超出太多的就砍,相反的如果你只能踢掉三題,那麼即使跟大家差很多,還是要留下來
檢查的方式,使用次數分配表裡面的描述統計來看遺漏值(偏態和峰度要自己打勾),選好所有的題目進框框,看第一題的框框,遺漏值=5代表有第一題五個人漏答了,請整理每個題目是甚麼,漏答率有多少
要整理成表格可以在輸出的表格點兩下,藉由右鍵→樞軸→轉置,就會左邊列是題目,右邊是,偏態的標準誤、峰度、峰度的標準誤都可以可以刪除
遺漏值有些問卷有提供非常滿意、滿意、不滿意、非常不滿意、無法作答,此時無法作答跟沒答都列為遺漏值
(會有無法作答是因為這個問卷的特性,並不是每個都問卷都需要)
通常遺漏值可以用個位數的最大值例如9,通常一開始就要設定遺漏值是多少(例如年齡,就寫99是遺漏值)
系統遺漏跟無法作答會歸類在一起
用item analysis這個檔案,以後要用預試就可以用這個檔案的格式
改一下編輯→選項→輸出標記改成「值與標記」可以看到每個代表什麼(1=非常同意,2=同意.....)
kelley統計學者提出是用前27%和最後27%作為界線是最有鑑別度,首先找總分多少,再來用百分位數用第73百分位數(PR=73),只要大於等於PR73的都叫做高分組,再找到PR只要低於27的都叫做低分組
如果兩組的平均數差異比較,用獨立樣本T考驗,如果有前後測但是是同一組,用相依樣本T考驗
也就是假設高分組的平均和低分組的平均,應該要高分組的平均要顯著高於低分組的平均
如何找出適合的好試題保留?
小樣本分析是用來考驗兩組極端組的得分平均,步驟如下:
1. 計算每題的總分
2. 找出高低分組
3. 使用獨立樣本T考驗(如果不顯著就可以剔除)
有顯著考驗才算好試題
4. 判斷
除了看是否簡述外,大樣本時可以找critical ratio臨界比,把T值取絕對值,如果是大於三的才可以算是好試題
用compute
選百分位數
轉換
作法:
1. 轉換→計算變數→統計→mean(用mean而不是sum這樣會幫妳寫回1~4選項,而不是平均分數,會幫你踢掉遺漏質),新增一個total
2. 分析→敘述統計→次數分配表,選剛剛新增的total→統計量→百分位數=27和73
3. 轉換→重新編碼成不同變數→選total,名稱打上組別,標記為極端組分組,按下變更,再按新質與舊質,選範圍,值到highest,2.9904.選新值為2(高分組),再設低分組
在按確定
新的組別中有
不想看到小數點可以到變數檢視裡面把小數點的位數改為0,把值得部分寫好1=高分組
平均數的差異除以標準誤就是T值的概念
分析→獨立樣本T考驗
獨立樣本T考驗作法:
獨立樣本T考驗→選好所有題目過去,分組變數選極端組分組,使用指定的數值裡放1和2,放相反也沒關係,只是T值的正負問題
定義組別1放2(高分組),組別2放1(低分組),並不影響顯著差異,只是看高分組減低分組還是相反
每組的人數不太相同是正確的
看第二個表格獨立樣本檢定,看到t那欄,顯著性是p值,如果樣本是隨機抽取而來的,第二個變異數要同質,第三個要常態分配,這樣才能用t檢定
因此t值有兩個是因為,公式幫你校正
如果高分組都是3.59分,低分組又有1分又有3分
如果Levene的顯著性p值是大於0.05
以第一題為例,
F檢定 顯著性 t 自由度 顯著性(雙尾)
.238 .627 14.655(=14.66) .000
14.683
當F檢定旁的顯著性如果是大於0.05要看上面那個t的數字
如果是小於等於0.05要看下面那個t的數字
t要寫作 14.66***
因為顯著性雙尾如果小於0.5是*,小於0.1是**,小於0.01(.000代表0.0000000XXX)是***
最後要標回去14.66***
同質性檢驗要把態度構念的項目加總和全部題目的相關、行為構念的項目加總和全部題目的相關(都要高才對),不要把全部題目跟總分直接相關,除非他們構念完全相同
題目和總分的相關:
分析→尺度→信度分析→選50題。統計量那裏勾選刪除項目後之量尺摘要(出來的報表代表刪掉自己這題之後,其他題目和總分的平均數或相關),這樣的相關比自己和50題的相關更嚴謹,這是校正後的題目總分相關(扣掉自己了)
.944
考題舉例:
如果老師的題目標準是0.4,修正的項目總相關是0.4以下的題號就要刪除了
sort描述性統計量,可以算出Z分數
因素負荷量:
分析→維度縮減→因素→移入題目→萃取→主成分→固定因子數目:1,確定,報表請拉到最後,看成分矩陣a,填回因素負荷
因素分析法最起碼要0.3
刪題標準可以用:
用遺漏值5%:
平均數的上下範圍:敘述統計選total選平均數和標準差,用一個標準差之內2.71+0.47~2.71-0.47,=2.24~3.18,之外的叫做不好
標準差:越大越好,所以標準為0.83,小於等於0.83的要去掉(可以刪掉十個)
偏態希望可以常態分配,所以偏態係數絕對值大於1的不能要(都可以要)
極端組t檢定(臨界比)若用3(看絕對值)只能刪掉幾題,甚至可以
相關:0.3以下的刪除(含0.3)
所以每題被圈了幾次,圈很多就很不好,老師會問如果只能刪1題,刪第5題會刪掉哪些題目
--
12.11
老師說測量研究第三個作業,如果你的論文用不到這樣的測驗工具,那可以兩人一組,如果論文題目也訂了
難度分析,難度的數字越大代表越簡單,最高是1,也就是100% ,有兩種算法,第一種是通過的人佔全體多少比率,第二種算法是高分組裡面的通過人數除以高分組的人數加上低分組通過人除以低分組總人數再除以2(高分組的通過率+低分組的通過率再除以2)
鑑別度是高分組的答對率減低分組的答對率
先算總分,算出PR然後算出大於27
通過率:
1. 高分組低分組,選擇高分組算出答對的,用次數分配那些人答對,計算有芬的是那些人,最後相加除二,鑑別度則是兩個相減
2. 等級觀察值,選擇某一組看答對率,用分割檔案也可以,每個組別都幫你做一次
檔案在Item analysis壓縮檔中 diffically這個SPSS檔案:有十個題目,答對是1 ,如果你的題目是四個選項的可以用轉換,答對的給1,答錯的給0
要先算總分:轉換→計算變數→自己寫目標變數為total統計→點兩下sum 自己key v1 to v2 。(設立一個total的新變項)
轉換→等級觀察值→依據剛剛的total為變數,勾選1是低分組→自訂N個等分=3,不勾選等級,會多出一個Ntotal變項,到變數檢視裡面改一下成為極端組別,在”值”那裏設定數值註解,1=低分組,2=中間組,3=高分組
編輯→選項→一般裡面,把顯示標記改為顯示名稱
選只做高分組:
資料→選擇觀察值→如果滿足設定條件→點選極端組別 = 3(資料檢視裡面就會有好多題先打斜線不列入計算)
再
分析→敘述統計→次數分配表→選十題目→確定次數分配,計算出1有幾個,佔總人數多少,就是高分組的答對率
算出來第一題全部都答對
列在表11-7 某教師自編測驗各題目
把每題的1有多少百分比填入高分組百分比
只做低分組:
資料→選擇觀察值→如果滿足設定條件→點選極端組別 = 1
分析→敘述統計→次數分配表→選十題目→次數分配,計算出1有幾個,佔總人數多少,就是高分組的答對率
算出來第一題全部都答對
把(高分組百分比-低分組百分比)/2,就是難度
分割檔案:只需要做一次
資料→分割檔案→依群組組織輸出→選極端組別過來
敘述統計→選時題,就會有看到每題的低分組看百分比,再來是中間組(不用看),高分組比分比
作業二
第四頁的建議,前面兩點都是找文即可,第三點開始要自己寫,第四點可以看第三點哪裡有錯,所以如果你是研究者會怎麼樣
作業評論寫的
一、 測量什麼p92有答案,分四大量表,有幾個類別,各幾題
二、 分數代表
三、 名詞定義
要配合你要測的哪種項目,定義一種即可,同時要跟研究目的相同,例如題目講的是服務學習,設計的題目就不要寫個人、學校、社會類別,如果答題分數最高是學校,是否代表影響利社會行為是學校影響最大而非服務學習。這樣可能做出來不符合研究目的,但其實不是沒符合目的,而是題目放的
名詞定義裡面不能再放名詞,p9公共事務態度、社會關懷…..應另外定義,並沒有解釋清楚
P86他採用的田納西自我概念量表有八個項目,在p87,可以選擇局部,但是要符合你的題目是否適用,適用的都要放
重測信度會隨著時間的長短而影響,要寫出重測信度間隔的時間
沒有錯,值得注意重測信度要寫範圍,如果是折半信度,也要交代是怎麼折半的
小數點最好是取兩位,至少要統一
引用別人的工具還是要授權,至少要寫個mail請求修改引用,並且附在論文後面
P87人際關係量表用了大學生,但是你要檢核信度和效度,或者有文獻說明為何如果用大學生都只有.53~.69,那用到高中生,至少要有Cronbach a分數至少要0.7才好,而且題數已經那麼多還只有0.53,題數變少了信度只會更低
如果各方量表題數不同,但是你去算總分,然後說這個影響最大是不行的,最好題數相同,四點五點量表也要分開。最好使用標準分數、轉換過的分數才有意義
如果性別也是重要考量,預試和真正失測要寫出性別比,預試樣本的代表性很重要
做預試就是要作項目分析好用來刪題,裡面沒刪題僅給信度係數
P95概念不同不要跑總量信度所以.043根本不用放,可以跑個項目的總量表,如果明明看起來題目跟主題應該要很有關聯,可是跑出來0.4左右,代表可能要重跑一次,或者哪個環節有問題
--
研究工具問卷應有的品質
1. 體貼受試者;
答案不要在最後一面讓大家拼命翻來翻去
題幹不要跨頁
五點量表每頁都有非常同意、同意....的表頭
如果題目內容多可以送個XG記憶卡提高填答意願
不要讓受試者還要幫你買郵票
2. 專業性
排版專業
不要錯字
3. 題目清晰易懂
不要出看不懂得名詞
題目不要過長
紙的磅數如果雙面列印不要太輕,文字不要透過去
45
信度效度
6. 妥適的題目排列
從簡單到困難
年齡或地區有一定邏輯(小到大或者大到小、近到遠遠到近)
題目相近的要放同一個區塊
哪裡可以找到研究工具
獲得已出版研究工具之相關資訊
Mental Measurements Yearbook at
http://www.unl.edu/buros/
ETS Test Collection at
http://www.ets.org/test_link/about/
心理出版社 at http://www.psy.com.tw
測驗出版商之目錄
專業期刊
測量之教科書
專業團體
http://www.ets.org/
檢索工具是否已經有人發展了?
分量表是scores
然後有評論者詳細描述(光是評論就要花錢買)
在研究背景上也可以做信度效度,嚴格的說應該要計算,可以用重測的方式來檢驗,但是最好是在前面讓受試者感受、產生對這個測驗的重要,才不會想要亂填,預防比較重要,或者在其他方面增加他們的填答意願,例如送小禮物(我覺得星巴克的飲料卡之類的不錯)
描述統計跑標準分數、某組平均數標準差中數眾數
兩位評分者間的評分者信度
多位評分者
重測信度
內部一致性
折半基數或者偶數、前半或後半
項目分析
極端組比較
小樣本分析
百多之多少較高分低分組
在某些標準下要刪除那些題目
與題目總分相關
自變項總共__個,包括性別年齡婚姻....
依變項為XXX和XXXX和XXX
題目1.
若利用極端組檢驗法(取極端的三分之一)並以臨界比大於等於5,做為選題之標準,則鑑別度比較差應刪除的題目是_____
題目2.
若利用題目總分相關法,並以相關係數大於等於0.5作為選題標準,則應考慮刪除的題目是____
題目3.
給一個題目,教學前後看成效,請算出
自我效能前測總分第一名___第二名____第三名
自我效能前測Z分數第一名___第二名____第三名
自我效能前測T分數第一名___第二名____第三名
並且計算描述統計四捨五入後填表
因素分析
斯皮爾曼發明, Cattell發揚光大
因素分析法有分兩種
探索性因素分析 (exploratory factor analysis, EFA)
驗證性因素分析 (confirmatory factory analysis, CFA)
因素分析的步驟
一、確認能不能用因素分析
因素分析是希望得到題目和題目之間相關高不高來看,如果題目之間相關都很高,它們基本上都只有一個背後因素,如果都很低代表大家因素都不同,那也不用抽了,期待看到有高有低會比較理想
淨相關是指單純自己那一題,排除掉其他題目(例如有三題,我想知道第一題的淨相關,代表第一題和第二題的相關,扣除掉第一和第二第三題共同的相關...可以用交集聯集概念來看)
反映像相關取絕對值就是淨相關,如果跑出來因素分析中的淨相關很大很大,那應該放棄使用因素分析
那麼就可以用
Bartlett的球形考驗 (test of sphericity
如果它的數據大而0則代表它可以用來做因素分析,如果不顯著的話也可以不用跑因素分析
Kaiser的抽樣適切性指數 (Kaiser-Meyer-Olkin measure of sampling adequacy; 簡稱 KMO 或 MSA)
如果十個題目每題之間的相關都很高,代表背後的因素很高,它是把所有兩兩的相關加起來,除以每一個的淨相關,希望越大越好,越適合進行進行因素分析,KMO或MSA指標0.7以上代表它可以跑因素分析
1. 因素分析條件:
並不是每個量化都可以跑因素分析,如果是名義,次數都不能跑
可以跑因素分析依定要比例或者連續變項,要是隨機並且樣本夠大(至少100,200,或者最長的分量表題數乘以5、10....至少200分會比較穩定)
二、決定抽幾個因素
抽取的方法
因素抽取的方法
1. 主成份分析法 (principal component analysis):以變異數分析為導向,選擇一組彼此獨立的成分,以簡化原來的資料關係,並儘可能解釋變項原來之變異量
2. 主軸因素法 (principal axis factoring):以共變數分析為導向,目的在藉由變項間的內部相關,找出並解釋共同變異量,以反映變項間潛在的基本結構或因素,以解釋變項間之相關
因素個數的決定
1.可以從特徵值 (eigenva1ue)判斷:特徵值代某一因素可解釋的總變異量,特徵值越大,代表該因素的解釋力越強。特徵值需大於1,才可被視為一個因素。低於1的特徵值,代表該因素的變異數少於單一變項的變異數1,無法以因素的形式存在。
2. Cattell’s的檢定是由圖形來判斷,所以稱Cattell’s陡坡檢定 (scree test):以繪圖方式檢定保留幾個因素的方法。其判斷標準是找出特徵值突然驟降之轉折彎角,在該彎角以上的幾個特徵值就是可保留下來的因數個數
殘差相關係數 (residual correlation coefficients):由共同因素所求得的變項與變項間之再製相關係數(reproduced correlation coefficients) 與原來變項間的相關係數之差為殘差相關係數,殘差相關係數愈小,表示因數分析愈成功
Y軸是特徵質,X軸是因素個數,畫出來之後看從很陡變成很緩的轉折點是在哪裡,對應出來是幾個個數就是我們要保留的因素個數
三、經過轉軸確認
是經過三角函數來計算,以直交轉軸(確定因素之間是互斥的、沒有關聯的),或者斜交轉軸(因素之間是有相關的)
四、確認之後命名,因素的命名需要一些創意和對內含的了解來扣住構念
SPSS跑因素分析:
分析
微度縮減
因子
選十個題目
萃取
主軸因子
陡坡圖要打勾
選轉軸法
斜交prom......
依據因素負荷量排序
隱藏較小的
絕對值低於0.3
確定
看報表
因素分析
要抽出題目背後共同的結構,找到彼此之間的相關,如果題目都不一樣,就會抽出好多好多因素
條件:一定要是連續變相而且符合線性
用兩種方式來檢驗是否適合用因素分析:
1. 使用巴特雷的球形考驗test of sphericity,看看有沒有顯著地高於0才可以做後續的因素分析
2. 或者使用凱瑟的抽樣適切性指數KMO如果背後有共同結構,會在0~1之間,數字越大越適合進行因素分析。0.9以上是極適合,08以上是適合,0.7以上是尚可,0.6是勉強,0.5是不適合,0.5以下:極不適合
抽因數(用何種方法、抽幾個)
1. 主成分分析法看是否能反映同一個因素,希望能解釋來的變異量
2. 主軸因素法找出內部的相關來解釋共同變異的情形
特徵值:代表此一因素可以解釋幾道題目可以反映的變異量,所以至少要大於一,至少能解釋一個題目(如果連解釋一個題目都達不到,那也不用)
Cattell’s 陡坡圖
是找到因數的個數為X軸,Y軸為特徵質,假設有十個題目,第一個因素可以解釋四個題目,特徵質是4,第二個因素的特徵質是3….把線段連起來之後就可以判斷幾個因素個數是合理的,由陡變緩的轉折就是應該保留下來的因素個數
如果轉折遇到1以下的請找前一個,至少要大於1
檢驗陡坡圖把幾個因素帶入特徵質試試看
經過轉軸可以確立如果因素相關的數值過近,經過直角轉軸(或斜交)後
如果你的論文中兩個因素完全沒有關係就用直角轉軸,如果兩個因素有關係就用斜交轉軸
可以選在第一個因素中有哪些題目,排序多到少,可以選擇sorted by size(因因素負荷量排序),這樣比較方便看由最多影響的和最少影響的
還有可以點選隱藏較少的係數0.3左右以下小於1的就不會顯示了
題號打在第一格,題目打在標記
先選一下選項→輸出→輸出標記標籤頁→名稱與標記,確定
分析→維度縮減→選題目過去→(不要放背景變向進來,只要找試題內容)
第一個步驟描述性統計→勾選係數(會有第一題和第一題的兩兩相關、第一題和第二題的兩兩相關,看有幾題就有幾個)
顯著水準則是第一題和第一題是否顯著、第一題和第二題的是否顯著……
KMO與Batterlett的球形檢定
殘差相關矩陣式要勾選重製的(較困難老師不教)
描述性統計量也要勾選第一個選項才會有描述統計平均數和標準差與個數(可以看出排除幾個觀察值,在選項裡面有)
第二個步驟萃取,使用主成分分析法的話不太好,在七中當中應該使用主軸因子會比較好(邱浩振老師裡面的書都有寫錯喔,應該都用主軸因子法)
要抽取幾個因素,可以根據特徵質並大於1,另外可以透過勾選陡坡圖來看。如果自己有確定幾個因子可以直接寫數字(薪資對加班費、導師費的滿意度)
再來第三個要寫轉軸法:如果假設因子之間是沒有相關的,有相關的請選擇最大變異法是正交轉軸,promax是斜交轉軸法,按下繼續
請勾選根據因素負荷排序、隱藏較小,絕對值低於3的(就隱藏不要出現)
本來有十題,勾了因子分析裡面的因素存成變數,那按下確定之後可能就會增加變成13個變項。當然也可以看出男生女生不同,可以把性別放入選擇變數欄位,就會分別幫你跑
接下來看KMO與Battelett先看顯著性,是有顯著的,代表整體而言這些試題有顯著的相關性質
Kaiser取樣適切0.879代表適合做因素分析
接著看報表反映像矩陣取樣適切性輛數MSA看報表上斜對角的數字(右上角有個小a的數字)(也是0.7以上就可以因素分析),如果有低於0.7,那麼再做一次,不要把這題丟進去跑
共同性報表請看萃取的,代表把這題當依變相,其他題是自變項去做多元回歸來預測,去找出這一題和其他題群的相關,稱為多元相關R,一個題目和另一個題目的相關叫簡單相關r,多元相關的平方就是決定係數,就看第一題和其他題共同的部分有多少?共同性越大代表重要性越高,適合因素分析
解說總變異量報表裡面,有十個題目應該會有十個因子,看總數那攔,第一個因素可以解釋幾題,等一下輸入幾個因子就由此判斷
看陡坡圖中油斗變緩是介於兩個或三個因素,搭配剛剛的特徵質是否小於1,小於1就不要,來決定到底有輸入幾個因子
因此因素矩陣就從10個變成2個了
因素負荷量是在因子矩陣的報表,如果有空白代表小於0.3(剛剛自己的設定),如果某個題目跟因素1和2都很接近,判斷會有困難,這時候就要做轉軸
轉軸之後會有兩個矩陣pattern matri樣式矩陣(是利用淨回歸和淨相關,看的是相對重要性)和 structure matrix結構矩陣(因素1裡有哪些試題、因素2…)
基本上先看結構矩陣,如果仍難判別,在看樣式矩陣
結構矩陣中排列過後假設因素1的數字都比因素2大,前面六題都是,因素2比因素1大的時候,則下半部,就可以畫一條線切開,因素1有哪些題目,因素2有那些數字
矩陣式樣式可以看要保留幾題
只要選擇斜交轉軸,就會算出兩者相關,呈現在因子相關矩陣,
最後的因子命名,可以看結構矩陣,會發現因子1的題目假設都是正向的,因子2的題目假設都是負向的,依據文獻,這時候可以將這兩個因子命名為正向的....負向的....(都要依據文獻與對論文的了解來命名)


請先 登入 以發表留言。